embedding niewielką przestrzeń, w której można tłumaczyć wielowymiarowych wektorów. Do dyskusji na temat różnic w wymiarach niskowymiarowych, patrz sekcja Kategoryczny Dane .
Wektory dystrybucyjne ułatwiają korzystanie z systemów uczących się na dużych urządzeniach. wektorów cech, takich jak ponieważ rozproszone wektory reprezentują produkty omówione poprzednia sekcja. Najlepiej, gdy wektor dystrybucyjny obejmuje część zbiorów semantykę danych wejściowych przez umieszczenie danych wejściowych, które są bardziej podobne pod względem znaczenia, w obszarze osadzania. Na przykład dobry osadzony element powinien zawierać tag słowo „samochód” Blisko „garażu” niż „słoń”. Wektor dystrybucyjny można wytrenować i ponownie wykorzystywane w różnych modelach.
Aby zrozumieć, w jaki sposób wektory dystrybucyjne reprezentują informacje, przeanalizujmy po jednowymiarowym odzwierciedleniu potraw hot dog, pizza, sałatka, szoarmę, barszcz, w skali „najmniej jak kanapka” lub „jak kanapka”. „Sandwichness” to pojedynczy wymiar.

Gdzie w tym wierszu występuje
strudel jabłkowy
upadek? Może znajdować się między hot dog a shawarma. Jabłko
strudel zdaje się mieć dodatkowy wymiar słodkości (ale
jedzenie) lub desery (podobne do deseru), które sprawia,
bardzo różni się od innych opcji. Ilustracja poniżej przedstawia to
dodając „deser”, wymiar:
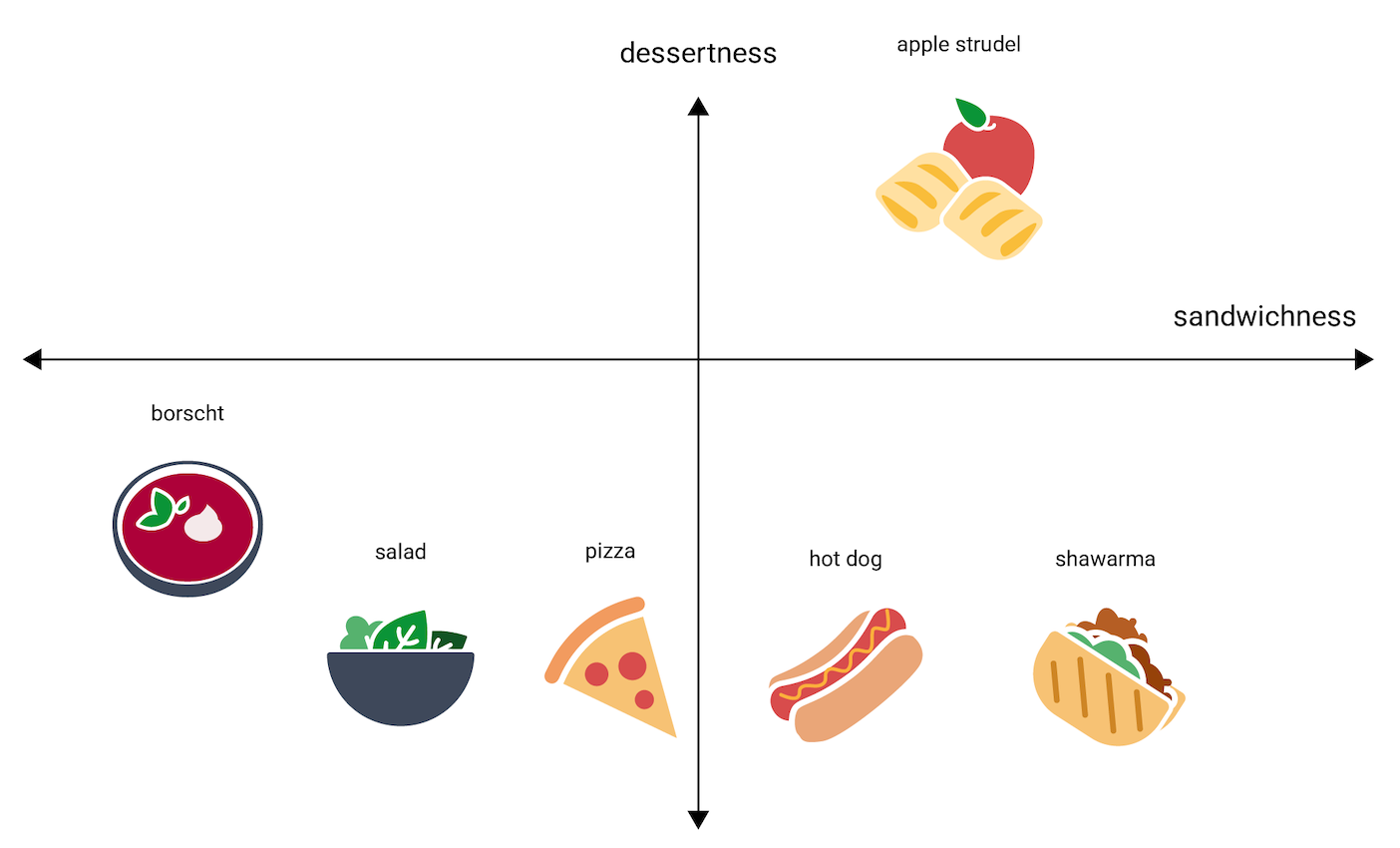
Wektor dystrybucyjny reprezentuje każdy element w przestrzeni n z oznaczeniem n. liczby zmiennoprzecinkowe (zwykle w zakresie od 1 do 1 lub 0 do 1). Na przykład umieszczenie na Rysunku 4 przedstawia każdy element posiłku w dwuwymiarową przestrzeń z dwiema współrzędnymi. Produkt „strudel jabłkowy” jest w prawą górną ćwiartkę wykresu i można ją przypisać do punktu (0,5; 0,3), a „hot dog” znajduje się w prawej dolnej ćwiartce wykresu i można mu przypisać punkt (0,2, –0,5).
We wektorze dystrybucyjnym można obliczyć odległość między dowolnymi dwoma elementami
matematycznie,
i można je interpretować jako względne podobieństwo obu tych elementów
elementy(ów). Dwie rzeczy, które są blisko siebie, np. shawarma i hot dog
na rys. 4, są bliżej powiązane niż 2 rzeczy bardziej oddalone
inne, takie jak apple strudel i borscht.
Warto zauważyć, że w przestrzeni 2D na rys. 4 obszar apple strudel jest znacznie dalej
od shawarma i hot dog niż w przestrzeni 1D, która odpowiada
intuicja: apple strudel nie jest tak straszny jak hot dog czy szoarma
psy i szoarmę są do siebie nawzajem.
Weźmy na przykład barszcz, który jest znacznie bardziej płynny niż inne produkty. Ten sugeruje trzeci wymiar, płynność (płynność żywności). Dodanie tego wymiaru umożliwia wizualizację elementów w 3D w następujący sposób:

Gdzie w tej przestrzeni 3D Tangyuan? Jest cukier, barszcz czy słodki deser, taki jak strudel jabłkowy. a nie kanapkę. Oto jedno z możliwych miejsc docelowych:
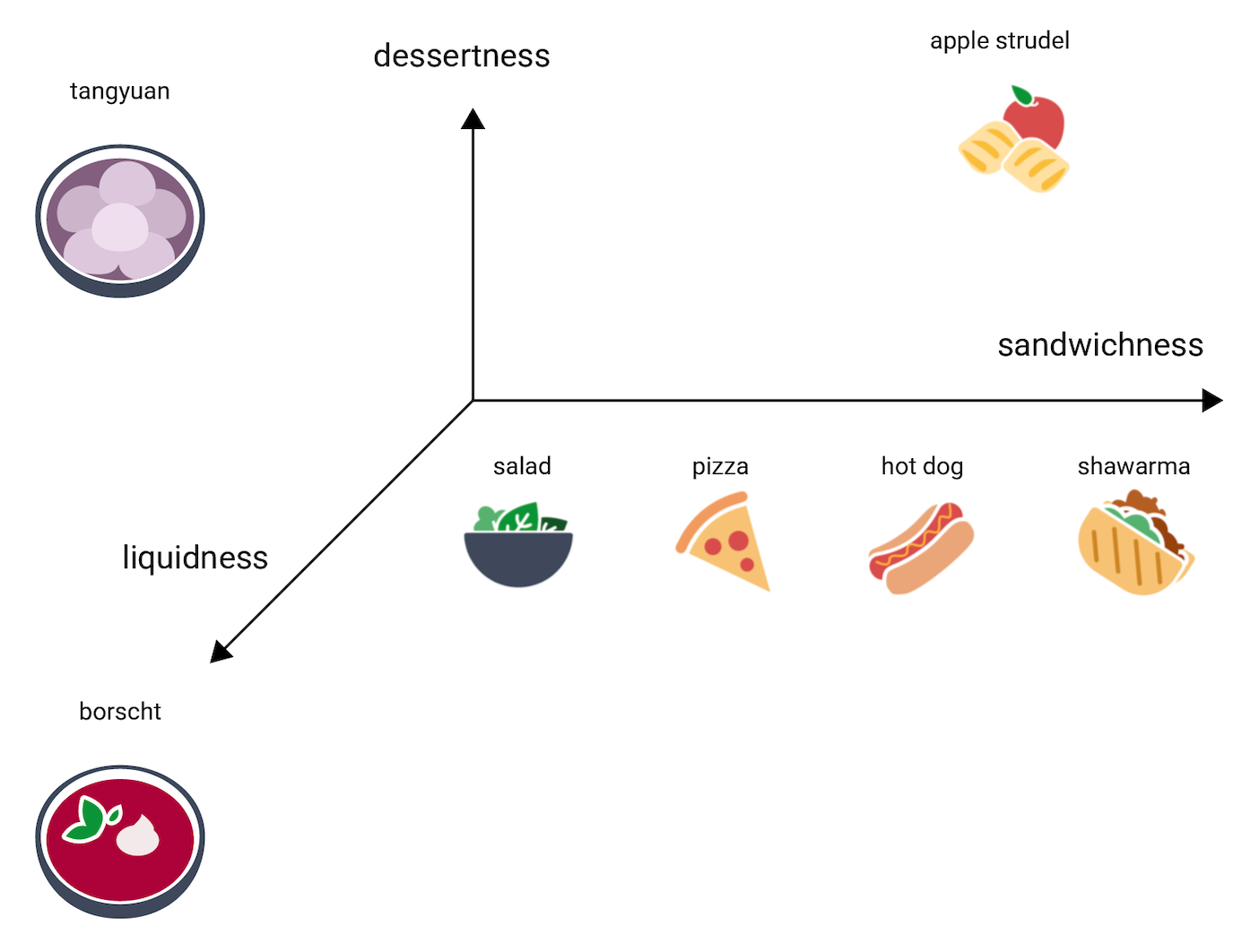
Zwróć uwagę, ile informacji jest wyrażonych w tych 3 wymiarach. Możesz dodać kolejne wymiary, takie jak mięso czy pieczenie.
Praktyczne przestrzenie
Jak widać na powyższych przykładach, nawet mała, wielowymiarowa przestrzeń zapewnia swobodę grupowania semantycznie podobnych elementów i przechowywania w odległości niepodobnych elementów. Położenie (odległość i kierunek) w wektorze może ona kodować semantykę w poprawnym wektorze dystrybucyjnym. Na przykład: wizualizacje prawdziwych wektorów dystrybucyjnych ilustrują zależności geometryczne między słowami oznaczającymi kraj i jego stolicę. Jak widać, odległość z „Kanada” do „Ottawa” jest mniej więcej taki sam jak odległość z Turcji do „Ankara”.

Znacząca przestrzeń wektorowa pomaga modelowi systemów uczących się wykrywać wzorce podczas trenowania.
Ćwiczenie
W tym ćwiczeniu użyjesz metody Umieszczanie Narzędzie projektora do wizualizacji słowa wektor dystrybucyjny o nazwie word2vec, który oznacza cyfrowo ponad 70 000 angielskich słów w przestrzeni wektorowej.
Zadanie 1
Wykonaj poniższe zadania, a następnie odpowiedz na pytanie poniżej.
Otwórz narzędzie Umieszczanie projektora.
W polu Szukaj w panelu po prawej stronie wpisz słowo atom. Potem kliknij słowo atom w poniższych wynikach (w sekcji 4 dopasowania). Twoje powinien wyglądać jak na ilustracji 8.

Rysunek 8. Osadzanie narzędzia projektora ze słowem „atom” Dodano w polu wyszukiwania (zakreślone na czerwono). Jeszcze raz w panelu po prawej stronie kliknij przycisk Izoluj 101 punktów (powyżej w polu Szukaj), aby wyświetlić 100 słów do argumentu atom. ekran, powinien wyglądać jak na rysunku 9.
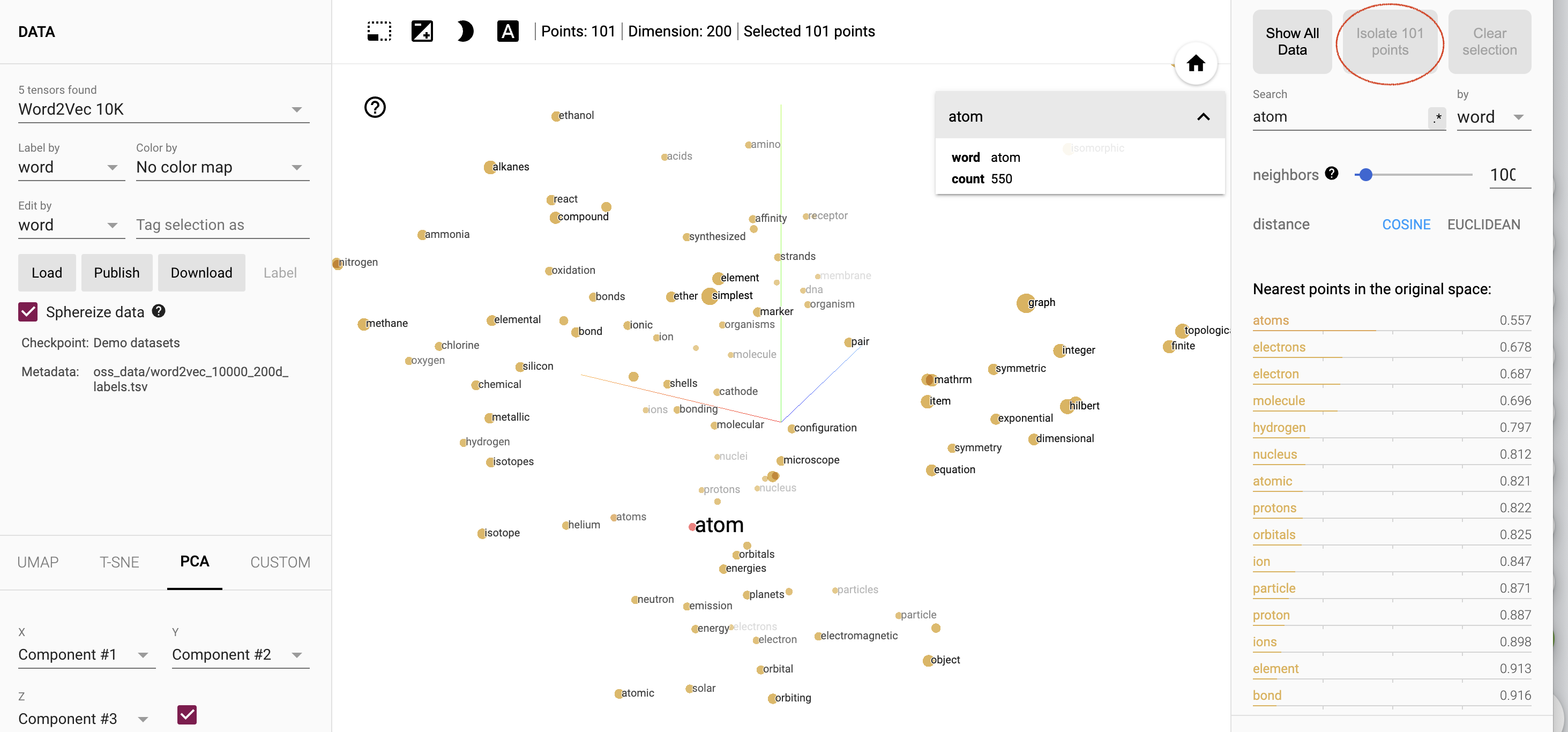
Rysunek 9. Umieszczanie narzędzia projektora, teraz z funkcją „Izoluj 101 punktów” kliknięty (zakreślony na czerwono).
Teraz przejrzyj słowa wymienione w sekcji Najbliższe punkty w oryginalnym miejscu. Jak możesz opisać te słowa?
Kliknij tutaj, aby poznać odpowiedź
Większość najbliższych słów to słowa powszechnie kojarzone ze słowem „atom”, np. w formie liczby mnogiej „atomy”, a słowa „elektron”, „molekule”, i „jądro atomowe”.
Zadanie 2
Wykonaj te zadania, a następnie odpowiedz na pytanie:
Kliknij przycisk Pokaż wszystkie dane w panelu po prawej stronie, aby zresetować dane. wizualizacji z zadania 1.
W polu Szukaj w panelu po prawej stronie wpisz słowo uran. Twój ekran powinien wyglądać jak na ilustracji 10.

Rysunek 10. Osadzanie projektora ze słowem „uran” w polu wyszukiwania.
Sprawdź słowa wymienione w sekcji Najbliższe punkty w oryginalnym miejscu. Jak Czy te słowa różnią się od najbliższych słów oznaczających atom?
Kliknij tutaj, aby poznać odpowiedź
Uran oznacza określony materiał radioaktywny pierwiastek chemiczny, wiele najbliższych słów to inne pierwiastki, takie jak cynk, mangan, miedzią i aluminium.
Zadanie 3
Wykonaj te zadania, a następnie odpowiedz na pytanie:
Kliknij przycisk Pokaż wszystkie dane w panelu po prawej stronie, aby zresetować dane. wizualizacji z zadania 2.
W panelu po prawej stronie w polu Szukaj wpisz wyraz pomarańczowy. Twoje powinien wyglądać jak na ilustracji 11.
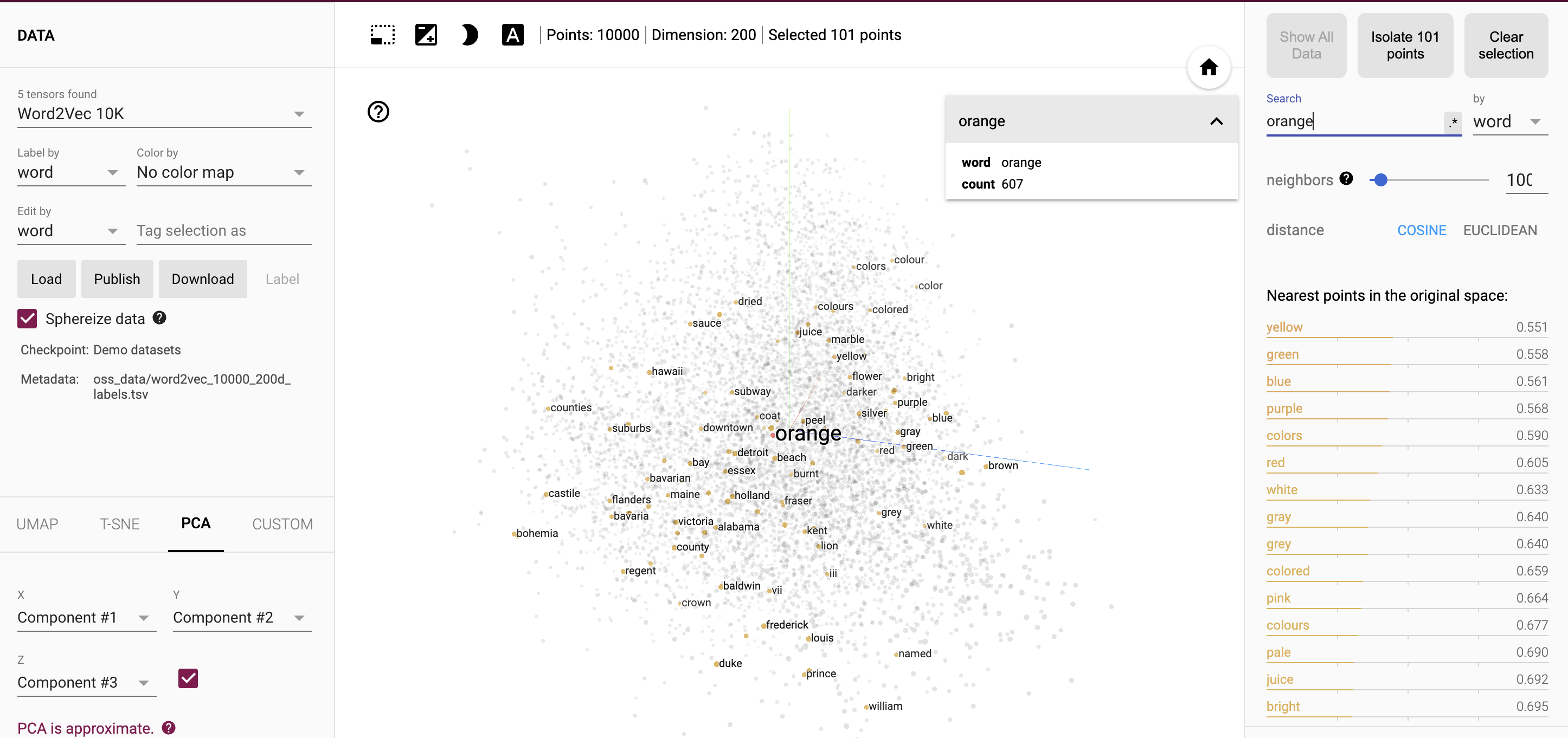
Rysunek 11. Umieszczanie narzędzia projektora ze słowem „pomarańczowy” w polu wyszukiwania.
Sprawdź słowa wymienione w sekcji Najbliższe punkty w oryginalnym miejscu. Co zwraca uwagę na rodzaj wyświetlanych tutaj słów lub ich rodzaj? nie jest tutaj uwzględnione?
Kliknij tutaj, aby poznać odpowiedź
Prawie wszystkie najbliższe słowa to inne kolory, na przykład „żółty” „zielony”, „niebieski”, „fioletowy”, i „czerwony”. tylko jedno z najbliższych słów („sok”) odnosi się do innego znaczenia słowa (owoc cytrusowy). Inne owoce których możesz się spodziewać, np. „jabłko” i „banan”, nie znalazł(a) się na liście najbliższe wartości.
Ten przykład ilustruje jeden z głównych wad wektorów dystrybucyjnych statycznych np. word2vec. Wszystkie możliwe znaczenia słowa są reprezentowane przez jedno w przestrzeni wektorowej. Kiedy przeprowadzisz analizę podobieństw dla koloru pomarańczowego, to nie można wyodrębnić najbliższych punktów dla określonego oznaczenia słowa, na przykład „pomarańczowy” (owoc), ale nie „pomarańczowy” (kolor).