На этой странице содержится глоссарий терминов по основам машинного обучения. Чтобы просмотреть все термины глоссария, нажмите здесь .
А
точность
Количество правильных прогнозов классификации, разделенное на общее количество прогнозов. То есть:
Например, модель, которая сделала 40 правильных прогнозов и 10 неправильных прогнозов, будет иметь точность:
Бинарная классификация дает конкретные названия различным категориям правильных и неправильных прогнозов . Итак, формула точности бинарной классификации выглядит следующим образом:
где:
- TP — количество истинных положительных результатов (правильных прогнозов).
- TN — количество истинных негативов (правильных прогнозов).
- FP — количество ложных срабатываний (неверных прогнозов).
- FN — количество ложноотрицательных результатов (неверных прогнозов).
Сравните и сопоставьте точность с точностью и отзывом .
функция активации
Функция, которая позволяет нейронным сетям изучать нелинейные (сложные) связи между объектами и меткой.
Популярные функции активации включают в себя:
Графики функций активации никогда не представляют собой одиночные прямые линии. Например, график функции активации ReLU состоит из двух прямых:

График сигмовидной функции активации выглядит следующим образом:

Нажмите на значок, чтобы увидеть пример.
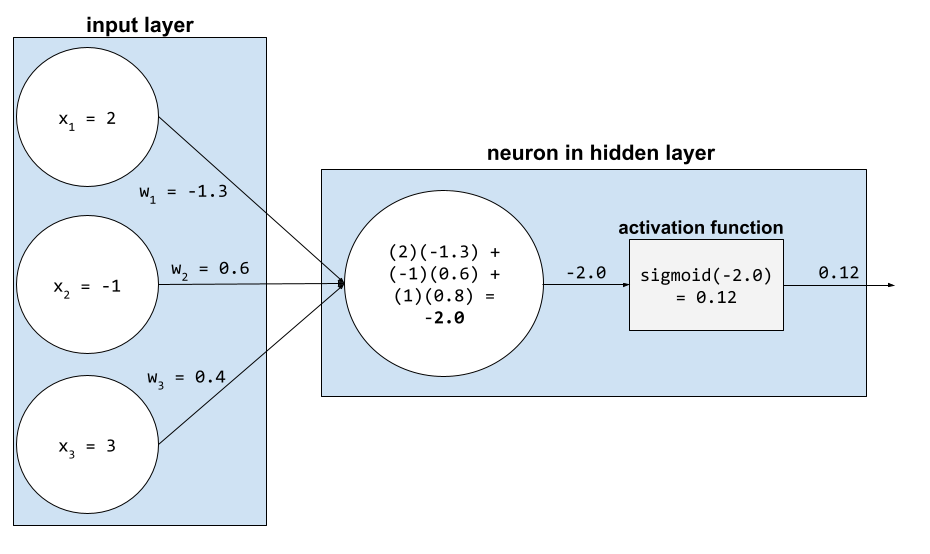
В нейронной сети функции активации манипулируют взвешенной суммой всех входных данных нейрона . Чтобы вычислить взвешенную сумму, нейрон складывает произведения соответствующих значений и весов. Например, предположим, что соответствующие входные данные для нейрона состоят из следующего:
| входное значение | входной вес |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0Предположим, разработчик этой нейронной сети выбирает сигмовидную функцию в качестве функции активации. В этом случае нейрон вычисляет сигмовидную величину -2,0, что составляет примерно 0,12. Следовательно, нейрон передает 0,12 (а не -2,0) на следующий уровень нейронной сети. Следующий рисунок иллюстрирует соответствующую часть процесса:
искусственный интеллект
Нечеловеческая программа или модель , способная решать сложные задачи. Например, программа или модель, которая переводит текст, или программа или модель, которая идентифицирует заболевания по радиологическим изображениям, обладают искусственным интеллектом.
Формально машинное обучение — это подобласть искусственного интеллекта. Однако в последние годы некоторые организации начали использовать термины «искусственный интеллект» и «машинное обучение» как синонимы.
AUC (Площадь под кривой ROC)
Число от 0,0 до 1,0, обозначающее способность модели бинарной классификации отделять положительные классы от отрицательных классов . Чем ближе AUC к 1,0, тем лучше способность модели отделять классы друг от друга.
Например, на следующем рисунке показана модель классификатора, которая идеально отделяет положительные классы (зеленые овалы) от отрицательных классов (фиолетовые прямоугольники). Эта нереально идеальная модель имеет AUC 1,0:

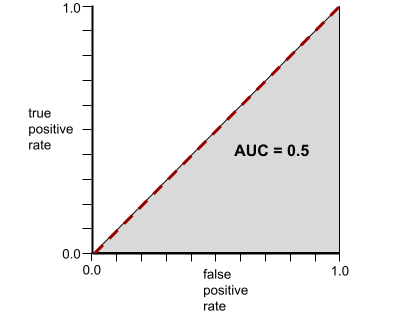
И наоборот, на следующем рисунке показаны результаты для модели классификатора, которая генерировала случайные результаты. Эта модель имеет AUC 0,5:

Да, предыдущая модель имеет AUC 0,5, а не 0,0.
Большинство моделей находятся где-то между двумя крайностями. Например, следующая модель несколько отделяет положительные значения от отрицательных и поэтому имеет AUC где-то между 0,5 и 1,0:

AUC игнорирует любые значения, установленные вами для порога классификации . Вместо этого AUC учитывает все возможные пороги классификации.
Щелкните значок, чтобы узнать о взаимосвязи между кривыми AUC и ROC.
AUC представляет собой площадь под кривой ROC . Например, кривая ROC для модели, которая идеально отделяет позитивы от негативов, выглядит следующим образом:
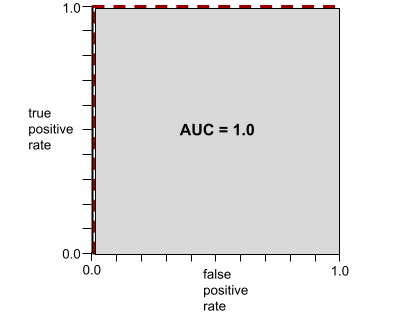
AUC — это площадь серой области на предыдущем рисунке. В этом необычном случае площадь представляет собой просто длину серой области (1,0), умноженную на ширину серой области (1,0). Таким образом, произведение 1,0 и 1,0 дает AUC ровно 1,0, что является максимально возможным показателем AUC.
И наоборот, кривая ROC для классификатора, который вообще не может разделять классы, выглядит следующим образом. Площадь этой серой области равна 0,5.
Более типичная кривая ROC выглядит примерно так:
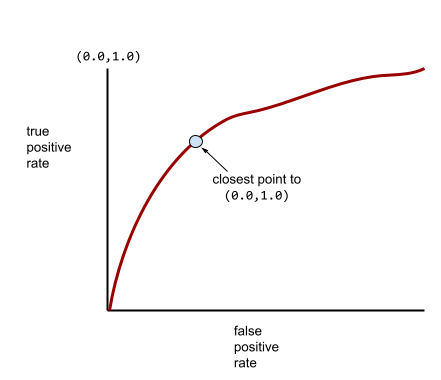
Было бы сложно вычислить площадь под этой кривой вручную, поэтому большинство значений AUC обычно рассчитывает программа.
Б
обратное распространение ошибки
Алгоритм, реализующий градиентный спуск в нейронных сетях .
Обучение нейронной сети включает в себя множество итераций следующего двухпроходного цикла:
- Во время прямого прохода система обрабатывает пакет примеров для получения прогнозов. Система сравнивает каждый прогноз с каждым значением метки . Разница между прогнозом и значением метки является потерей для этого примера. Система суммирует потери для всех примеров, чтобы вычислить общие потери для текущей партии.
- Во время обратного прохода (обратного распространения ошибки) система уменьшает потери, корректируя веса всех нейронов во всех скрытых слоях .
Нейронные сети часто содержат множество нейронов во многих скрытых слоях. Каждый из этих нейронов по-разному вносит свой вклад в общую потерю. Обратное распространение ошибки определяет, следует ли увеличивать или уменьшать веса, применяемые к конкретным нейронам.
Скорость обучения — это множитель, который контролирует степень увеличения или уменьшения каждого веса при каждом обратном проходе. Большая скорость обучения будет увеличивать или уменьшать каждый вес больше, чем низкая скорость обучения.
С точки зрения исчисления, обратное распространение ошибки реализует правило цепочки . из исчисления. То есть обратное распространение ошибки вычисляет частную производную ошибки по каждому параметру.
Несколько лет назад специалистам по машинному обучению приходилось писать код для реализации обратного распространения ошибки. Современные API машинного обучения, такие как TensorFlow, теперь реализуют обратное распространение ошибки. Уф!
партия
Набор примеров , используемых в одной обучающей итерации . Размер партии определяет количество примеров в партии.
См. «Эпоха» для объяснения того, как партия связана с эпохой.
размер партии
Количество примеров в пакете . Например, если размер пакета равен 100, модель обрабатывает 100 примеров за итерацию .
Ниже приведены популярные стратегии размера партии:
- Стохастический градиентный спуск (SGD) , в котором размер пакета равен 1.
- Полный пакет, в котором размер пакета — это количество примеров во всем обучающем наборе . Например, если обучающий набор содержит миллион примеров, то размер пакета будет составлять миллион примеров. Полная партия обычно является неэффективной стратегией.
- мини-пакет , размер которого обычно составляет от 10 до 1000. Мини-пакет обычно является наиболее эффективной стратегией.
предвзятость (этика/справедливость)
1. Стереотипы, предрассудки или фаворитизм в отношении одних вещей, людей или групп по сравнению с другими. Эти предубеждения могут повлиять на сбор и интерпретацию данных, дизайн системы и то, как пользователи взаимодействуют с системой. К формам этого типа предвзятости относятся:
- предвзятость автоматизации
- предвзятость подтверждения
- предвзятость экспериментатора
- предвзятость групповой атрибуции
- неявная предвзятость
- внутригрупповая предвзятость
- предвзятость в отношении однородности чужой группы
2. Систематическая ошибка, вызванная процедурой выборки или отчетности. К формам этого типа предвзятости относятся:
- смещение охвата
- предвзятость в связи с отсутствием ответов
- предвзятость участия
- предвзятость в отчетности
- смещение выборки
- предвзятость отбора
Не путать с термином «предвзятость» в моделях машинного обучения или «предвзятость прогнозирования» .
предвзятость (математика) или термин предвзятости
Перехват или смещение от начала координат. Смещение — это параметр в моделях машинного обучения, который обозначается одним из следующих символов:
- б
- ш 0
Например, смещение — это буква b в следующей формуле:
В простой двумерной линии смещение означает просто «пересечение оси Y». Например, смещение линии на следующем рисунке равно 2.
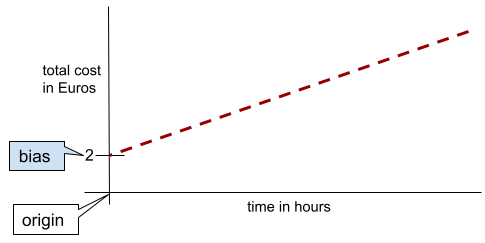
Смещение существует, потому что не все модели начинаются с начала координат (0,0). Например, предположим, что вход в парк развлечений стоит 2 евро и дополнительно 0,5 евро за каждый час пребывания клиента. Следовательно, модель, отображающая общую стоимость, имеет смещение 2, поскольку минимальная стоимость составляет 2 евро.
Предвзятость не следует путать с предвзятостью в вопросах этики и справедливости или предвзятостью прогнозирования .
бинарная классификация
Тип задачи классификации , которая прогнозирует один из двух взаимоисключающих классов:
Например, каждая из следующих двух моделей машинного обучения выполняет двоичную классификацию:
- Модель, определяющая, являются ли сообщения электронной почты спамом (положительный класс) или нет (негативный класс).
- Модель, которая оценивает медицинские симптомы, чтобы определить, есть ли у человека определенное заболевание (положительный класс) или нет этого заболевания (негативный класс).
Сравните с многоклассовой классификацией .
См. также логистическую регрессию и порог классификации .
группирование
Преобразование одного объекта в несколько двоичных объектов, называемых сегментами или контейнерами , обычно на основе диапазона значений. Вырезанный объект обычно является непрерывным объектом .
Например, вместо того, чтобы представлять температуру как один непрерывный признак с плавающей запятой, вы можете разбить диапазоны температур на отдельные сегменты, например:
- <= 10 градусов по Цельсию будет «холодным» ведром.
- 11–24 градуса по Цельсию будет «умеренным» ведром.
- >= 25 градусов по Цельсию будет «теплым» ведром.
Модель будет обрабатывать каждое значение в одном и том же сегменте одинаково. Например, значения 13 и 22 относятся к сегменту умеренного климата, поэтому модель обрабатывает эти два значения одинаково.
С
категориальные данные
Функции , имеющие определенный набор возможных значений. Например, рассмотрим категориальную функцию под названием traffic-light-state , которая может иметь только одно из следующих трех возможных значений:
-
red -
yellow -
green
Представляя traffic-light-state как категориальную характеристику, модель может изучить различное влияние red , green и yellow на поведение водителя.
Категориальные признаки иногда называют дискретными признаками .
Сравните с числовыми данными .
сорт
Категория, к которой может принадлежать метка . Например:
- В модели двоичной классификации , которая обнаруживает спам, двумя классами могут быть спам и не спам .
- В многоклассовой модели классификации , которая идентифицирует породы собак, классами могут быть пудель , бигль , мопс и так далее.
Модель классификации предсказывает класс. Напротив, регрессионная модель предсказывает число, а не класс.
модель классификации
Модель , предсказание которой является классом . Например, ниже приведены все модели классификации:
- Модель, которая предсказывает язык входного предложения (французский? испанский? итальянский?).
- Модель, предсказывающая породы деревьев (клен? дуб? баобаб?).
- Модель, которая прогнозирует положительный или отрицательный класс конкретного заболевания.
Напротив, регрессионные модели предсказывают числа, а не классы.
Два распространенных типа классификационных моделей:
порог классификации
В двоичной классификации - число от 0 до 1, которое преобразует необработанные выходные данные модели логистической регрессии в прогноз либо положительного , либо отрицательного класса . Обратите внимание, что порог классификации — это значение, которое выбирает человек, а не значение, выбранное при обучении модели.
Модель логистической регрессии выводит необработанное значение от 0 до 1. Затем:
- Если это необработанное значение превышает порог классификации, то прогнозируется положительный класс.
- Если это необработанное значение меньше порога классификации, то прогнозируется отрицательный класс.
Например, предположим, что порог классификации равен 0,8. Если исходное значение равно 0,9, модель прогнозирует положительный класс. Если исходное значение равно 0,7, то модель прогнозирует отрицательный класс.
Выбор порога классификации сильно влияет на количество ложноположительных и ложноотрицательных результатов .
несбалансированный по классам набор данных
Набор данных для задачи классификации, в которой общее количество меток каждого класса значительно различается. Например, рассмотрим набор данных двоичной классификации, две метки которого разделены следующим образом:
- 1 000 000 негативных ярлыков
- 10 положительных ярлыков
Соотношение отрицательных и положительных меток составляет 100 000 к 1, поэтому это набор данных с несбалансированным классом.
Напротив, следующий набор данных не является несбалансированным по классам, поскольку соотношение отрицательных меток к положительным меткам относительно близко к 1:
- 517 отрицательных ярлыков
- 483 положительных метки
Многоклассовые наборы данных также могут быть несбалансированными по классам. Например, следующий набор данных многоклассовой классификации также несбалансирован по классам, поскольку одна метка содержит гораздо больше примеров, чем две другие:
- 1 000 000 этикеток класса «зеленый»
- 200 этикеток класса «фиолетовый».
- 350 этикеток класса «оранжевый».
См. также энтропию , класс большинства и класс меньшинства .
вырезка
Техника обработки выбросов путем выполнения одного или обоих следующих действий:
- Уменьшение значений функций , превышающих максимальный порог, до этого максимального порога.
- Увеличение значений функций, которые меньше минимального порога, до этого минимального порога.
Например, предположим, что <0,5% значений определенного признака выходят за пределы диапазона 40–60. В этом случае вы можете сделать следующее:
- Обрежьте все значения выше 60 (максимальный порог), чтобы они составляли ровно 60.
- Обрежьте все значения ниже 40 (минимальный порог), чтобы они составляли ровно 40.
Выбросы могут повредить модели, иногда вызывая переполнение весов во время обучения. Некоторые выбросы также могут существенно испортить такие показатели, как точность . Обрезка — распространенный метод ограничения ущерба.
Отсечение градиента приводит к тому, что значения градиента находятся в пределах заданного диапазона во время обучения.
матрица путаницы
Таблица NxN, в которой суммируется количество правильных и неправильных прогнозов, сделанных моделью классификации . Например, рассмотрим следующую матрицу путаницы для модели бинарной классификации :
| Опухоль (прогнозируемая) | Неопухолевый (прогнозируемый) | |
|---|---|---|
| Опухоль (основная правда) | 18 (ТП) | 1 (ФН) |
| Не опухоль (основная правда) | 6 (ФП) | 452 (Теннесси) |
Предыдущая матрица путаницы показывает следующее:
- Из 19 прогнозов, в которых основной истиной была опухоль, модель правильно классифицировала 18 и неправильно классифицировала 1.
- Из 458 прогнозов, в которых основной истиной было отсутствие опухоли, модель правильно классифицировала 452 и неправильно классифицировала 6.
Матрица путаницы для задачи классификации нескольких классов может помочь вам выявить закономерности ошибок. Например, рассмотрим следующую матрицу путаницы для трехклассовой многоклассовой модели классификации, которая классифицирует три разных типа радужной оболочки (Вирджиника, Версиколор и Сетоза). Когда основной истиной была Вирджиния, матрица путаницы показывает, что модель с гораздо большей вероятностью ошибочно предсказывала Версиколор, чем Сетозу:
| Сетоза (прогноз) | Разноцветный (предсказано) | Вирджиния (прогнозируется) | |
|---|---|---|---|
| Сетоза (основная правда) | 88 | 12 | 0 |
| Версиколор (основная правда) | 6 | 141 | 7 |
| Вирджиния (основная правда) | 2 | 27 | 109 |
Еще один пример: матрица путаницы может показать, что модель, обученная распознавать рукописные цифры, имеет тенденцию ошибочно предсказывать 9 вместо 4 или ошибочно предсказывать 1 вместо 7.
Матрицы ошибок содержат достаточно информации для расчета различных показателей производительности, включая точность и полноту .
непрерывный объект
Функция с плавающей запятой с бесконечным диапазоном возможных значений, таких как температура или вес.
Контраст с дискретной функцией .
конвергенция
Состояние, при котором значения потерь изменяются очень незначительно или вообще не меняются на каждой итерации . Например, следующая кривая потерь предполагает сходимость примерно через 700 итераций:
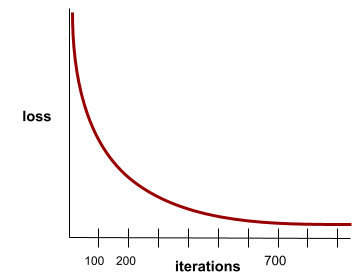
Модель сходится , когда дополнительное обучение не улучшает модель.
При глубоком обучении значения потерь иногда остаются постоянными или почти постоянными в течение многих итераций, прежде чем, наконец, упасть. В течение длительного периода постоянных значений потерь у вас может временно возникнуть ложное ощущение конвергенции.
См. также раннюю остановку .
Д
DataFrame
Популярный тип данных pandas для представления наборов данных в памяти.
DataFrame аналогичен таблице или электронной таблице. Каждый столбец DataFrame имеет имя (заголовок), а каждая строка идентифицируется уникальным номером.
Каждый столбец в DataFrame структурирован как двумерный массив, за исключением того, что каждому столбцу можно назначить свой собственный тип данных.
См. также официальную справочную страницу pandas.DataFrame .
набор данных или набор данных
Коллекция необработанных данных, обычно (но не исключительно) организованная в одном из следующих форматов:
- электронная таблица
- файл в формате CSV (значения, разделенные запятыми)
глубокая модель
Нейронная сеть , содержащая более одного скрытого слоя .
Глубокую модель еще называют глубокой нейронной сетью .
Контраст с широкой моделью .
плотная особенность
Функция , в которой большинство или все значения не равны нулю, обычно это тензор значений с плавающей запятой. Например, следующий 10-элементный тензор является плотным, поскольку 9 его значений не равны нулю:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
Контраст с редкими функциями .
глубина
Сумма следующего в нейронной сети :
- количество скрытых слоев
- количество выходных слоев , которое обычно составляет 1
- количество любых слоев внедрения
Например, нейронная сеть с пятью скрытыми слоями и одним выходным слоем имеет глубину 6.
Обратите внимание, что входной слой не влияет на глубину.
дискретная функция
Объект с конечным набором возможных значений. Например, признак, значения которого могут быть только «животное» , «растение » или «минерал» , является дискретным (или категориальным) признаком.
Контраст с непрерывной функцией .
динамичный
Что-то, что делается часто или постоянно. Термины динамический и онлайн являются синонимами в машинном обучении. Ниже приведены распространенные варианты использования динамического и онлайн- обучения в машинном обучении:
- Динамическая модель (или онлайн-модель ) — это модель, которая часто или непрерывно переобучается.
- Динамическое обучение (или онлайн-обучение ) — это процесс частого или непрерывного обучения.
- Динамический вывод (или онлайн-вывод ) — это процесс генерации прогнозов по требованию.
динамическая модель
Модель , которая часто (возможно, даже постоянно) переобучается. Динамическая модель — это «обучение на протяжении всей жизни», которое постоянно адаптируется к меняющимся данным. Динамическая модель также известна как онлайн-модель .
Контраст со статической моделью .
Э
ранняя остановка
Метод регуляризации , который предполагает прекращение обучения до того, как перестанут уменьшаться потери при обучении. При ранней остановке вы намеренно прекращаете обучение модели, когда потери в наборе проверочных данных начинают увеличиваться; то есть, когда производительность обобщения ухудшается.
слой внедрения
Специальный скрытый слой , который обучается на многомерном категориальном признаке для постепенного изучения вектора внедрения более низкого измерения. Слой внедрения позволяет нейронной сети обучаться гораздо эффективнее, чем обучение только на многомерном категориальном признаке.
Например, на Земле в настоящее время произрастает около 73 000 видов деревьев. Предположим, что виды деревьев являются признаком вашей модели, поэтому входной слой вашей модели включает в себя вектор длиной 73 000 элементов. Например, возможно, baobab можно было бы представить примерно так:

Массив из 73 000 элементов очень длинный. Если вы не добавите в модель слой внедрения, обучение займет очень много времени из-за умножения 72 999 нулей. Возможно, вы выберете слой внедрения, состоящий из 12 измерений. Следовательно, слой внедрения постепенно изучает новый вектор внедрения для каждой породы деревьев.
В определенных ситуациях хеширование является разумной альтернативой слою внедрения.
эпоха
Полный проход обучения по всему обучающему набору , при котором каждый пример обрабатывается один раз.
Эпоха представляет собой N / итераций обучения размера пакета , где N — общее количество примеров.
Например, предположим следующее:
- Набор данных состоит из 1000 примеров.
- Размер партии — 50 экземпляров.
Следовательно, для одной эпохи требуется 20 итераций:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
пример
Значения одной строки объектов и, возможно, метки . Примеры контролируемого обучения делятся на две общие категории:
- Помеченный пример состоит из одного или нескольких объектов и метки. Маркированные примеры используются во время обучения.
- Немаркированный пример состоит из одного или нескольких объектов, но без метки. Во время вывода используются немаркированные примеры.
Например, предположим, что вы обучаете модель для определения влияния погодных условий на результаты тестов учащихся. Вот три помеченных примера:
| Функции | Этикетка | ||
|---|---|---|---|
| Температура | Влажность | Давление | Оценка теста |
| 15 | 47 | 998 | Хороший |
| 19 | 34 | 1020 | Отличный |
| 18 | 92 | 1012 | Бедный |
Вот три немаркированных примера:
| Температура | Влажность | Давление | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
Строка набора данных обычно является необработанным источником примера. То есть пример обычно состоит из подмножества столбцов набора данных. Кроме того, объекты в примере также могут включать в себя синтетические объекты , такие как перекрестные объекты .
Ф
ложноотрицательный (ЛН)
Пример, в котором модель ошибочно предсказывает отрицательный класс . Например, модель предсказывает, что конкретное сообщение электронной почты не является спамом (негативный класс), но на самом деле это сообщение электронной почты является спамом .
ложноположительный результат (FP)
Пример, в котором модель ошибочно предсказывает положительный класс . Например, модель предсказывает, что конкретное сообщение электронной почты является спамом (положительный класс), но на самом деле это сообщение электронной почты не является спамом .
уровень ложноположительных результатов (FPR)
Доля реальных отрицательных примеров, для которых модель ошибочно предсказала положительный класс. Следующая формула рассчитывает уровень ложноположительных результатов:
Частота ложноположительных результатов — это ось X на кривой ROC .
особенность
Входная переменная модели машинного обучения. Пример состоит из одной или нескольких функций. Например, предположим, что вы обучаете модель для определения влияния погодных условий на результаты тестов учащихся. В следующей таблице показаны три примера, каждый из которых содержит три функции и одну метку:
| Функции | Этикетка | ||
|---|---|---|---|
| Температура | Влажность | Давление | Оценка теста |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
Контраст с этикеткой .
особенность креста
Синтетический признак , образованный путем «пересечения» категориальных или группированных признаков.
Например, рассмотрим модель «прогноза настроения», которая представляет температуру в одном из следующих четырех сегментов:
-
freezing -
chilly -
temperate -
warm
И представляет скорость ветра в одном из следующих трех сегментов:
-
still -
light -
windy
Без перекрестия функций линейная модель обучается независимо на каждом из семи предыдущих сегментов. Итак, модель тренируется, например, freezing независимо от тренировки, например, windy .
В качестве альтернативы вы можете создать перекрестную функцию температуры и скорости ветра. Эта синтетическая функция будет иметь следующие 12 возможных значений:
-
freezing-still -
freezing-light -
freezing-windy -
chilly-still -
chilly-light -
chilly-windy -
temperate-still -
temperate-light -
temperate-windy -
warm-still -
warm-light -
warm-windy
Благодаря крестикам функций модель может запоминать разницу в настроении между freezing-windy и freezing-still днем.
Если вы создадите синтетический объект из двух объектов, каждый из которых имеет множество разных сегментов, полученный кросс объектов будет иметь огромное количество возможных комбинаций. Например, если один объект имеет 1000 сегментов, а другой — 2000 сегментов, результирующий кросс объектов будет иметь 2 000 000 сегментов.
Формально крест — это декартово произведение .
Перекрещивания признаков в основном используются с линейными моделями и редко используются с нейронными сетями.
разработка функций
Процесс, который включает в себя следующие этапы:
- Определение того, какие функции могут быть полезны при обучении модели.
- Преобразование необработанных данных из набора данных в эффективные версии этих функций.
Например, вы можете решить, что temperature может быть полезной функцией. Затем вы можете поэкспериментировать с группированием , чтобы оптимизировать то, что модель может узнать из разных temperature диапазонов.
Инжиниринг функций иногда называют извлечением функций или реализацией функций.
набор функций
Группа функций, на которых тренируется ваша модель машинного обучения. Например, почтовый индекс, размер и состояние недвижимости могут составлять простой набор функций для модели, прогнозирующей цены на жилье.
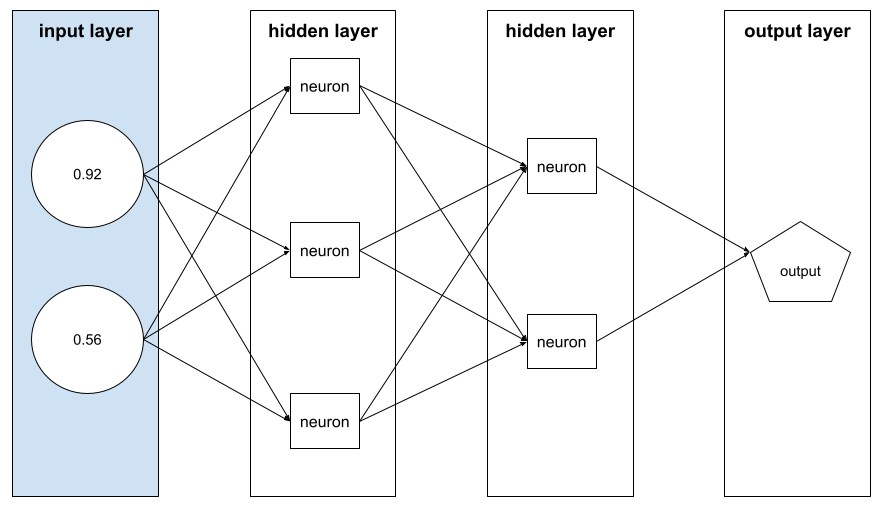
вектор признаков
Массив значений признаков , содержащий пример . Вектор признаков вводится во время обучения и во время вывода . Например, вектор признаков для модели с двумя дискретными признаками может быть следующим:
[0.92, 0.56]
В каждом примере предоставляются разные значения вектора признаков, поэтому вектор признаков для следующего примера может выглядеть примерно так:
[0.73, 0.49]
Разработка признаков определяет, как представлять объекты в векторе признаков. Например, двоичный категориальный признак с пятью возможными значениями может быть представлен с помощью горячего кодирования . В этом случае часть вектора признаков для конкретного примера будет состоять из четырех нулей и одного 1,0 в третьей позиции, как показано ниже:
[0.0, 0.0, 1.0, 0.0, 0.0]
В качестве другого примера предположим, что ваша модель состоит из трех функций:
- двоичный категориальный признак с пятью возможными значениями, представленными с помощью горячего кодирования; например:
[0.0, 1.0, 0.0, 0.0, 0.0] - Еще одна бинарная категориальная особенность с тремя возможными значениями, представленными с одним горячим кодированием; Например:
[0.0, 0.0, 1.0] - функция с плавающей точкой; Например:
8.3.
В этом случае вектор функций для каждого примера будет представлен девятью значениями. Учитывая примеры значений в предыдущем списке, вектор функций будет:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
обратная связь
В машинном обучении ситуация, в которой прогнозы модели влияют на учебные данные для той же модели или другой модели. Например, модель, которая рекомендует фильмы, будет влиять на фильмы, которые люди смотрят, что затем повлияет на последующие модели рекомендаций фильма.
Г
обобщение
Способность модели делать правильные прогнозы на новые, ранее невидимые данные. Модель, которая может обобщить, является противоположностью модели, которая переживает .
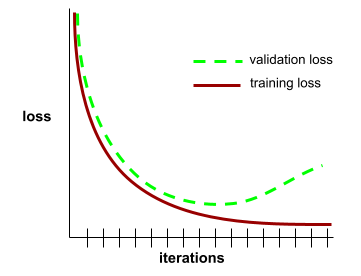
Кривая обобщения
Сюжет как потери обучения , так и потери проверки в зависимости от количества итераций .
Кривая обобщения может помочь вам обнаружить возможный переосмысление . Например, следующая кривая обобщения предполагает переосмысление, поскольку потеря проверки в конечном итоге становится значительно выше, чем потери тренировок.
градиентный спуск
Математический метод, чтобы минимизировать потерю . Градиент спуск итеративно регулирует веса и смещения , постепенно находя наилучшую комбинацию, чтобы минимизировать потерю.
Градиент спуск старше - намного старше, чем машинное обучение.
основная истина
Реальность.
То, что на самом деле произошло.
Например, рассмотрим модель бинарной классификации , которая предсказывает, будет ли студент на первом курсе университета в течение шести лет. Основная правда для этой модели заключается в том, действительно ли этот студент получил высшее образование в течение шести лет.
ЧАС
Скрытый слой
Слой в нейронной сети между входным уровнем (функциями) и выходным слоем (прогноз). Каждый скрытый слой состоит из одного или нескольких нейронов . Например, следующая нейронная сеть содержит два скрытых слоя, первый с тремя нейронами, а второй с двумя нейронами:
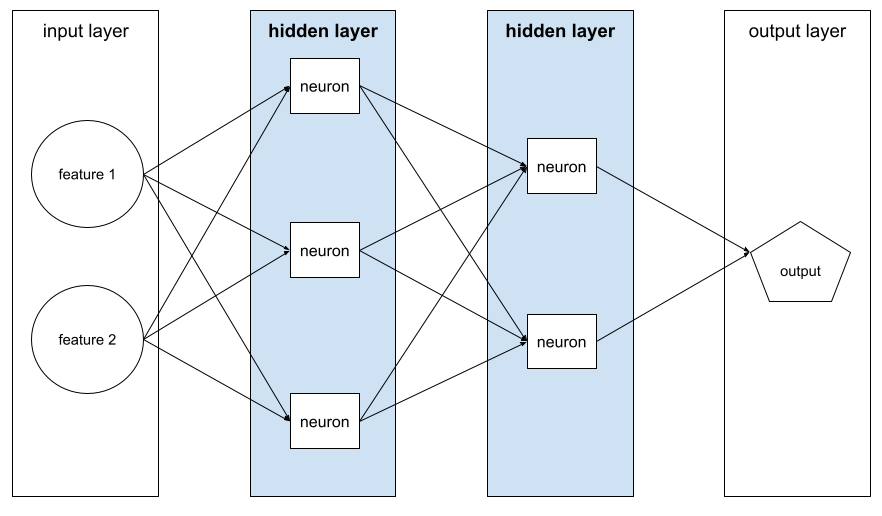
Глубокая нейронная сеть содержит более одного скрытого слоя. Например, предыдущая иллюстрация представляет собой глубокую нейронную сеть, потому что модель содержит два скрытых слоя.
гиперпараметр
Переменные, которые вы или служба настройки гиперпараметровПри скорректировке во время последовательных заездов обучения модели. Например, скорость обучения является гиперпараметром. Вы можете установить уровень обучения на 0,01 перед одной тренировкой. Если вы определите, что 0,01 слишком высока, вы можете установить скорость обучения на 0,003 для следующей тренировки.
Напротив, параметры - это различные веса и предвзятость , которые модель изучает во время обучения.
я
самостоятельно и идентично распределено (IID)
Данные, взятые из распределения, которое не изменяется, и где каждое нарисованное значение не зависит от значений, которые были нарисованы ранее. IID - это идеальный газ машинного обучения - полезная математическая конструкция, но почти никогда не встречается в реальном мире. Например, распространение посетителей на веб -страницу может быть IID в течение короткого окна времени; То есть распространение не меняется во время этого краткого окна, и визит одного человека, как правило, не зависит от визита другого. Однако, если вы расширяете это окно времени, могут появиться сезонные различия в посетителях веб -страницы.
См. Также нестационарность .
вывод
В машинном обучении процесс прогнозирования путем применения обученной модели к немеченым примерам .
Вывод имеет несколько иное значение в статистике. Смотрите статью Википедии о статистическом выводе для деталей.
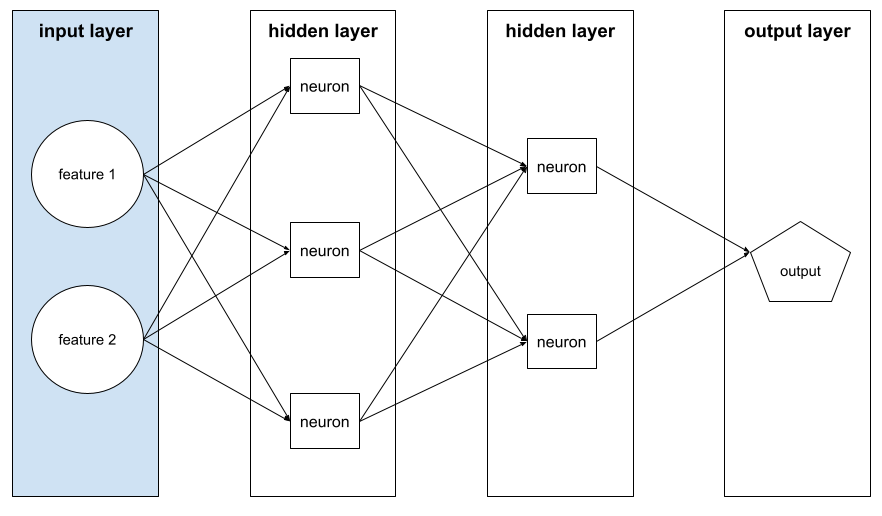
входной слой
Уровень нейронной сети , которая содержит вектор функций . То есть входной слой содержит примеры для обучения или вывода . Например, входной уровень в следующей нейронной сети состоит из двух функций:
интерпретируемость
Способность объяснять или представлять рассуждения модели ML в понятных терминах человеку.
Например, большинство моделей линейной регрессии очень интерпретируются. (Вам просто нужно взглянуть на обученные веса для каждой функции.) Леса принятия решений также хорошо интерпретируются. Некоторые модели, однако, требуют сложной визуализации, чтобы стать интерпретируемой.
Вы можете использовать инструмент интерпретации обучения (LIT) для интерпретации моделей ML.
итерация
Единое обновление параметров модели - веса модели и предвзятости - обучение . Размер партии определяет, сколько примеров обрабатывает модель в одной итерации. Например, если размер партии составляет 20, то модель обрабатывает 20 примеров перед настройкой параметров.
При обучении нейронной сети , одна итерация включает в себя следующие два прохода:
- Правный проход для оценки потери на одной партии.
- Обратный проход ( обратный процесс ) для корректировки параметров модели на основе потери и скорости обучения.
л
L 0 регуляризация
Тип регуляризации , который наказывает общее количество ненулевых весов в модели. Например, модель, имеющая 11 ненулевых весов, была бы оштрафована больше, чем аналогичная модель с 10 ненулевыми весами.
L 0 регуляризация иногда называют регуляризацией L0-Norm .
L 1 потеря
Функция потери , которая вычисляет абсолютное значение разницы между фактическими значениями метки и значениями, которые предсказывает модель . Например, вот расчет потери L 1 для партии из пяти примеров :
| Фактическое значение примера | Прогнозируемое значение модели | Абсолютное значение дельты |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L 1 потеря | ||
L 1 Потеря менее чувствительна к выбросам , чем потеря L 2 .
Средняя абсолютная ошибка - это средняя потеря L 1 на пример.
L 1 регуляризация
Тип регуляризации , который наказывает веса пропорционально сумме абсолютного значения весов. L 1 Ретализация помогает стимулировать вес неактуальных или едва соответствующих функций ровно 0 . Функция с весом 0 эффективно удалена из модели.
Контраст с регуляризацией L 2 .
L 2 потеря
Функция потери , которая вычисляет квадрат разницы между фактическими значениями метки и значениями, которые предсказывает модель . Например, вот расчет потери L 2 для партии из пяти примеров :
| Фактическое значение примера | Прогнозируемое значение модели | Квадрат Дельта |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L 2 потеря | ||
Из -за квадрата потери L 2 усиливают влияние выбросов . То есть потеря L 2 реагирует более сильно на плохие прогнозы, чем потеря L 1 . Например, потеря L 1 для предыдущей партии составит 8, а не 16. Обратите внимание, что один выброс учитывает 9 из 16.
Регрессионные модели обычно используют потерю L 2 в качестве функции потери.
Средняя квадратная ошибка - это средняя потеря L 2 за пример. Потери квадрата - это еще одно название для потери L 2 .
L 2 регуляризация
Тип регуляризации , который наказывает веса пропорционально сумме квадратов весов. L 2 Ретализация помогает стимулировать вес (те, которые с высокими положительными или низкими отрицательными значениями) ближе к 0, но не совсем до 0 . Особенности со значениями, очень близкими 0, остаются в модели, но не сильно влияют на прогноз модели.
L 2 Ретализация всегда улучшает обобщение в линейных моделях .
Контраст с регуляризацией L 1 .
этикетка
В контролируемом машинном обучении «ответ» или «Результат» часть примера .
Каждый помеченный пример состоит из одной или нескольких функций и метки. Например, в наборе данных обнаружения спама на этикетке, вероятно, будет либо «спам», либо «не спам». В наборе данных осадков этикетка может быть количество дождя, которое упало в течение определенного периода.
помеченный пример
Пример, который содержит одну или несколько функций и этикетку . Например, в следующей таблице показаны три помеченных примера из модели оценки дома, каждый с тремя функциями и одной меткой:
| Количество спален | Количество ванных комнат | Дом возраст | Цена дома (этикетка) |
|---|---|---|---|
| 3 | 2 | 15 | 345 000 долларов |
| 2 | 1 | 72 | 179 000 долларов |
| 4 | 2 | 34 | 392 000 долларов |
В контролируемом машинном обучении модели обучаются на маркированных примерах и делают прогнозы на немеченых примерах .
Контрастные помеченные пример с немечеными примерами.
лямбда
Синоним уровня регуляризации .
Lambda - это перегруженный термин. Здесь мы сосредотачиваемся на определении термина в рамках регуляризации .
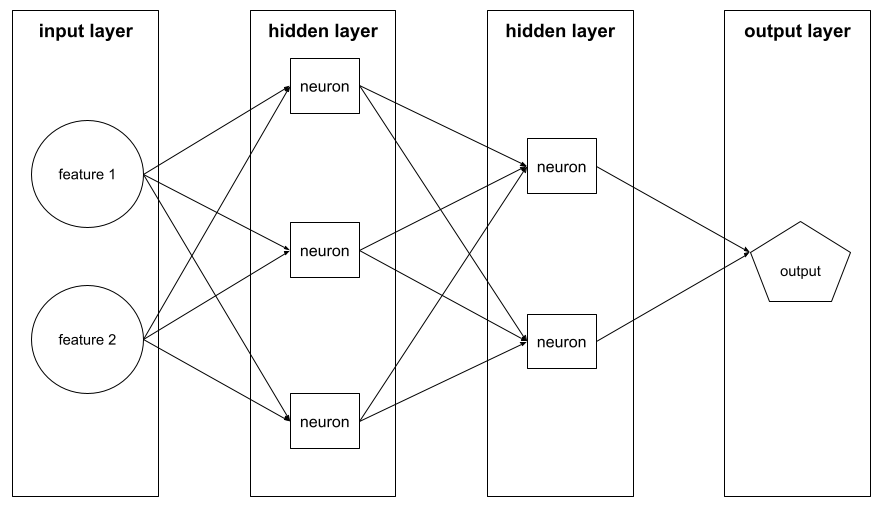
слой
Набор нейронов в нейронной сети . Три распространенных типа слоев следующие:
- Входной слой , который предоставляет значения для всех функций .
- Один или несколько скрытых слоев , которые находят нелинейные отношения между функциями и меткой.
- Выходной слой , который обеспечивает прогноз.
Например, на следующей иллюстрации показана нейронная сеть с одним входным уровнем, двумя скрытыми слоями и одним выходным слоем:
В TensorFlow слои также являются функциями Python, которые принимают тензоры и параметры конфигурации в качестве входного и производят другие тензоры в качестве вывода.
скорость обучения
Номер с плавающей запятой, который сообщает алгоритм градиентного спуска , насколько сильно регулировать веса и смещения на каждой итерации . Например, скорость обучения 0,3 будет корректировать вес и смещения в три раза более мощно, чем скорость обучения 0,1.
Уровень обучения является ключевым гиперпараметром . Если вы установите слишком низкую скорость обучения, обучение займет слишком много времени. Если вы устанавливаете слишком высокий уровень обучения, у градиентного спуска часто возникают проблемы с достижением сходимости .
линейный
Связь между двумя или более переменными, которые могут быть представлены исключительно посредством добавления и умножения.
Сюжет линейных отношений - это линия.
Контраст с нелинейным .
линейная модель
Модель , которая присваивает один вес на функцию для прогнозирования . (Линейные модели также включают в себя смещение .) Напротив, связь функций к прогнозам в глубоких моделях , как правило, нелинейная .
Линейные модели, как правило, легче тренировать и более интерпретируются , чем глубокие модели. Тем не менее, глубокие модели могут изучать сложные отношения между функциями.
Линейная регрессия и логистическая регрессия являются двумя типами линейных моделей.
линейная регрессия
Тип модели машинного обучения, в которой оба из следующих
- Модель является линейной моделью .
- Прогноз-это значение с плавающей точкой. (Это регрессионная часть линейной регрессии .)
Контрастная линейная регрессия с логистической регрессией . Кроме того, контрастная регрессия с классификацией .
логистическая регрессия
Тип регрессионной модели , которая предсказывает вероятность. Модели логистической регрессии имеют следующие характеристики:
- Этикетка категориальна . Термин логистическая регрессия обычно относится к бинарной логистической регрессии , то есть к модели, которая вычисляет вероятности для меток с двумя возможными значениями. Менее распространенный вариант, мультиномиальная логистическая регрессия , вычисляет вероятности для меток с более чем двумя возможными значениями.
- Функция потери во время обучения - потеря журнала . (Несколько единиц потери журнала могут быть размещены на параллели для меток с более чем двумя возможными значениями.)
- Модель имеет линейную архитектуру, а не глубокую нейронную сеть. Тем не менее, оставшаяся часть этого определения также применима к глубоким моделям , которые предсказывают вероятности категориальных меток.
Например, рассмотрим модель логистической регрессии, которая вычисляет вероятность того, что входное электронное письмо будет либо спамом, либо не спам. Во время вывода предположим, что модель предсказывает 0,72. Следовательно, модель оценивает:
- 72% шанс на спам.
- 28% вероятность того, что электронное письмо не является спамом.
Модель логистической регрессии использует следующую двухэтапную архитектуру:
- Модель генерирует необработанное прогноз (Y '), применяя линейную функцию входных функций.
- Модель использует этот необработанный прогноз в качестве входного вводного в сигмоидную функцию , которая преобразует необработанное прогноз в значение от 0 до 1, исключительно.
Как и любая модель регрессии, модель логистической регрессии предсказывает число. Однако это число обычно становится частью бинарной классификационной модели следующим образом:
- Если прогнозируемое число больше, чем порог классификации , модель бинарной классификации предсказывает положительный класс.
- Если прогнозируемое число меньше порога классификации, модель бинарной классификации предсказывает отрицательный класс.
Потеря
Функция потерь, используемая в бинарной логистической регрессии .
логарифмические
Логарифм шансов какого -то события.
потеря
Во время обучения контролируемой модели мера того, насколько далеко прогнозирование модели от его ярлыка .
Функция потери вычисляет потерю.
кривая потери
График потери как функция количества обучающих итераций . На следующем графике показана типичная кривая потерь:
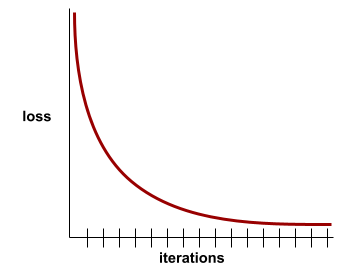
Кривые потерь могут помочь вам определить, когда ваша модель сходится или переживает .
Кривые потерь могут построить все следующие типы потерь:
См. Также кривая обобщения .
функция потерь
Во время обучения или тестирования математическая функция, которая вычисляет потерю на партии примеров. Функция потери возвращает более низкую потерю для моделей, которые делают хорошие прогнозы, чем для моделей, которые делают плохие прогнозы.
Цель обучения, как правило, состоит в том, чтобы минимизировать потери, которую возвращает функция потери.
Существует много различных видов потерь. Выберите соответствующую функцию потерь для той модели, которую вы строите. Например:
- L 2 Потеря (или средняя квадратная ошибка ) является функцией потери для линейной регрессии .
- Потеря журнала - это функция потери для логистической регрессии .
М
машинное обучение
Программа или система, которая обучает модель из входных данных. Обученная модель может сделать полезные прогнозы из новых (никогда не видно) данных, взятых из того же распределения, что и то, что используется для обучения модели.
Машинное обучение также относится к области исследования, связанной с этими программами или системами.
большинство класс
Более распространенная метка в классе-имбалансированном наборе данных . Например, учитывая набор данных, содержащий 99% отрицательных меток и 1% положительных меток, отрицательные этикетки - это большинство класса.
Контраст с классом меньшинства .
мини-партия
Небольшая, случайно выбранная подмножество партии , обработанного в одной итерации . Размер партии мини-партии обычно составляет от 10 до 1000 примеров.
Например, предположим, что весь учебный набор (полная партия) состоит из 1000 примеров. Кроме того, предположим, что вы устанавливаете размер партии каждой мини-партии на 20. Следовательно, каждая итерация определяет потерю на случайных 20 из 1000 примеров, а затем соответственно корректирует веса и смещения .
Гораздо эффективнее рассчитать потерю на мини-партии, чем потери всех примеров в полной партии.
класс меньшинства
Менее распространенная метка в класс-имбалансированном наборе данных . Например, учитывая набор данных, содержащий 99% отрицательных меток и 1% положительных меток, положительными этикетками являются класс меньшинства.
Контраст с классом большинства .
модель
В целом, любая математическая конструкция, которая обрабатывает входные данные и возвращает вывод. Фрагрировано иначе, модель - это набор параметров и структуры, необходимых для системы для прогнозирования. В контролируемом машинном обучении модель получает пример в качестве ввода и делает прогноз в качестве вывода. Внутри контролируемого машинного обучения модели несколько отличаются. Например:
- Модель линейной регрессии состоит из набора весов и предвзятости .
- Модель нейронной сети состоит из:
- Набор скрытых слоев , каждый из которых содержит один или несколько нейронов .
- Вес и смещение, связанные с каждым нейроном.
- Модель дерева решений состоит из:
- Форма дерева; то есть шаблон, при которой условия и листья соединены.
- Условия и листья.
Вы можете сохранить, восстановить или сделать копии модели.
Неконтролируемое машинное обучение также генерирует модели, как правило, функция, которая может отобразить входной пример с наиболее подходящим кластером .
Многоклассовая классификация
В контролируемом обучении задача классификации , в которой набор данных содержит более двух классов метки. Например, этикетки в наборе данных Iris должны быть одним из следующих трех классов:
- Радужная оболочка Сетоса
- Айрис Вирджиния
- Iris versicolor
Модель, обученная набору данных IRIS, которая прогнозирует тип IRIS на новых примерах,-это многоклассная классификация.
Напротив, проблемы классификации, которые различают ровно двух классов, являются моделями бинарной классификации . Например, модель электронной почты, которая прогнозирует либо спам , либо не спам, является моделью бинарной классификации.
В задачах кластеризации многоклассная классификация относится к более чем двум кластерам.
Н
отрицательный класс
В бинарной классификации один класс называется положительным , а другой называется отрицательным . Положительный класс - это то, что модель тестирует, а отрицательный класс - другая возможность. Например:
- Отрицательный класс в медицинском тесте может быть «не опухоль».
- Негативным классом в классификаторе электронной почты может быть «не спам».
Контраст с положительным классом .
нейронная сеть
Модель , содержащая хотя бы один скрытый слой . Глубокая нейронная сеть - это тип нейронной сети, содержащей более одного скрытого уровня. Например, на следующей диаграмме показана глубокая нейронная сеть, содержащая два скрытых слоя.
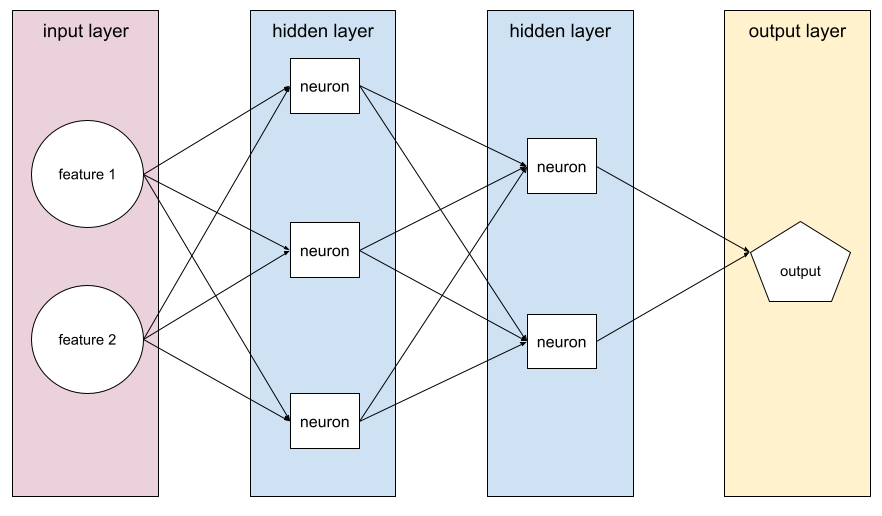
Каждый нейрон в нейронной сети подключается ко всем узлам в следующем уровне. Например, на предыдущей диаграмме обратите внимание, что каждый из трех нейронов в первом скрытом слое отдельно соединяется с обоими двумя нейронами во втором скрытом слое.
Нейронные сети, внедренные на компьютерах, иногда называют искусственными нейронными сетями, чтобы дифференцировать их от нейронных сетей, обнаруженных в мозге и других нервных системах.
Некоторые нейронные сети могут имитировать чрезвычайно сложные нелинейные отношения между различными функциями и меткой.
См. Также сверточная нейронная сеть и повторяющаяся нейронная сеть .
нейрон
В машинном обучении отличное устройство в скрытом слое нейронной сети . Каждый нейрон выполняет следующее двухэтапное действие:
- Вычисляет взвешенную сумму входных значений, умноженную на соответствующие веса.
- Передает взвешенную сумму в качестве входной функции в функцию активации .
Нейрон в первом скрытом слое принимает входы из значений функций в входном слое . Нейрон в любом скрытом слое за пределами первого принимает входные данные от нейронов в предыдущем скрытом слое. Например, нейрон во втором скрытом слое принимает входные данные от нейронов в первом скрытом слое.
Следующая иллюстрация подчеркивает два нейрона и их входные данные.
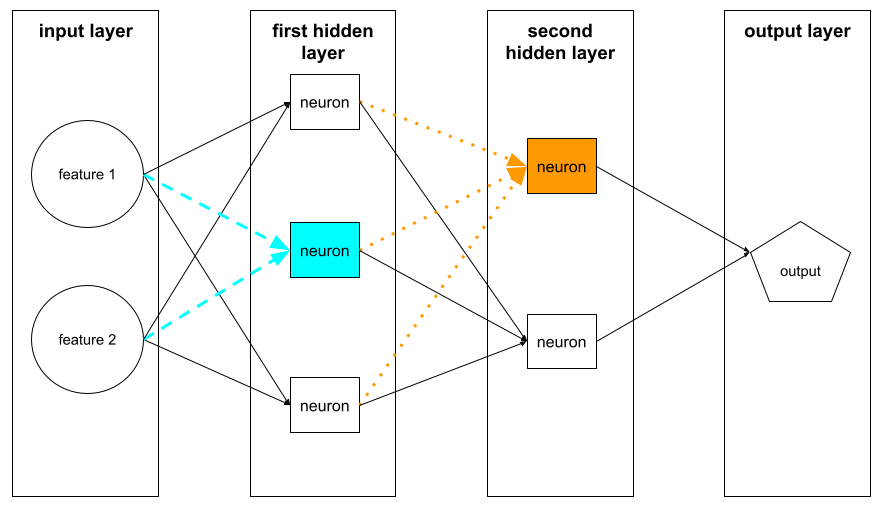
Нейрон в нейронной сети имитирует поведение нейронов в мозге и других частях нервных систем.
Узел (нейронная сеть)
Нейрон в скрытом слое .
нелинейный
Отношения между двумя или более переменными, которые не могут быть представлены исключительно через сложение и умножение. Линейная связь может быть представлена как линия; Нелинейные отношения не могут быть представлены как строка. Например, рассмотрим две модели, которые каждая связывает одну функцию с одной меткой. Модель слева линейна, а модель справа нелинейна:

нестационарность
Функция, значения которых изменяются по одному или нескольким измерениям, обычно время. Например, рассмотрим следующие примеры нестационарности:
- Количество купальников, проданных в конкретном магазине, зависит от сезона.
- Количество конкретного фрукта, собранного в конкретном регионе, составляет равное большую часть года, но большое количество в течение короткого периода.
- Из -за изменения климата, годовая средняя температура меняется.
Контрастировать со стационарностью .
нормализация
Вообще говоря, процесс преобразования фактического диапазона значений переменной в стандартный диапазон значений, таких как:
- -1 до +1
- от 0 до 1
- нормальное распределение
Например, предположим, что фактический диапазон значений определенной функции составляет от 800 до 2400. В рамках инженерии функций вы можете нормализовать фактические значения до стандартного диапазона, например от -1 до +1.
Нормализация является общей задачей в разработке функций . Модели обычно тренируются быстрее (и производят лучшие прогнозы), когда каждая численная особенность в векторе объектов имеет примерно одинаковый диапазон.
числовые данные
Особенности , представленные в виде целых чисел или реальных чисел. Например, модель оценки дома, вероятно, будет представлять размер дома (в квадратных футах или квадратных метрах) в качестве численных данных. Представление функции в качестве численных данных указывает на то, что значения функции имеют математическое отношение к этикетке. То есть количество квадратных метров в доме, вероятно, имеет некоторое математическое отношение к ценности дома.
Не все целочисленные данные должны быть представлены в виде числовых данных. Например, почтовые коды в некоторых частях мира являются целыми исходами; Тем не менее, целочисленные почтовые коды не должны быть представлены как числовые данные в моделях. Это связано с тем, что почтовый код 20000 не является дважды (или половиной) столь же мощным, как почтовый индекс 10000. Кроме того, хотя разные почтовые коды коррелируют с различными значениями недвижимости, мы не можем предположить, что значения недвижимости в почтовом коде 20000 в два раза больше ценно, чем значения недвижимости в почтовом коде 10000. Вместо этого почтовые коды должны быть представлены как категориальные данные .
Численные особенности иногда называют непрерывными функциями .
О
офлайн
Синоним статического .
автономный вывод
Процесс модели, генерирующей партию прогнозов , а затем кэширование (сохранение) этих прогнозов. Затем приложения могут получить доступ к предполагаемому прогнозу из кэша, а не повторять модель.
Например, рассмотрим модель, которая генерирует локальные прогнозы погоды (прогнозы) раз в четыре часа. После каждой модели запуска система кэширует все локальные прогнозы погоды. Погодные приложения извлекают прогнозы из кеша.
Вывод о автономном режиме также называется статическим выводом .
Контрастировать с онлайн -выводом .
горячее кодирование
Представляя категориальные данные как вектор, в котором:
- Один элемент установлен на 1.
- Все остальные элементы установлены на 0.
Одногоральное кодирование обычно используется для представления строк или идентификаторов, которые имеют конечный набор возможных значений. Например, предположим, что определенная категориальная функция с именем Scandinavia имеет пять возможных значений:
- "Дания"
- "Швеция"
- "Норвегия"
- "Финляндия"
- "Исландия"
Один-горячее кодирование может представлять каждое из пяти значений следующим образом:
| страна | Вектор | ||||
|---|---|---|---|---|---|
| "Дания" | 1 | 0 | 0 | 0 | 0 |
| "Швеция" | 0 | 1 | 0 | 0 | 0 |
| "Норвегия" | 0 | 0 | 1 | 0 | 0 |
| "Финляндия" | 0 | 0 | 0 | 1 | 0 |
| "Исландия" | 0 | 0 | 0 | 0 | 1 |
Благодаря однокачественному кодированию модель может изучать различные связи, основанные на каждой из пяти стран.
Представление функции в качестве численных данных является альтернативой однопольнуемому кодированию. К сожалению, представление скандинавских стран численно не является хорошим выбором. Например, рассмотрим следующее числовое представление:
- "Дания" - 0
- "Швеция" - 1
- "Норвегия" - 2
- "Финляндия" 3
- «Исландия» 4
При числовом кодировании модель математически интерпретирует необработанные числа и будет пытаться тренироваться на этих числах. Тем не менее, Исландия на самом деле не вдвое больше (или вдвое меньше) чего -то, чем Норвегия, поэтому модель сделает некоторые странные выводы.
One-Vs.-All
Учитывая проблему классификации с классами N, решение, состоящее из N отдельных бинарных классификаторов - одного двоичного классификатора для каждого возможного результата. Например, учитывая модель, которая классифицирует примеры как животные, овощные или минеральные, одно и все, что обеспечит следующие три отдельных бинарных классификаторов:
- animal versus not animal
- vegetable versus not vegetable
- mineral versus not mineral
онлайн
Synonym for dynamic .
online inference
Generating predictions on demand. For example, suppose an app passes input to a model and issues a request for a prediction. A system using online inference responds to the request by running the model (and returning the prediction to the app).
Contrast with offline inference .
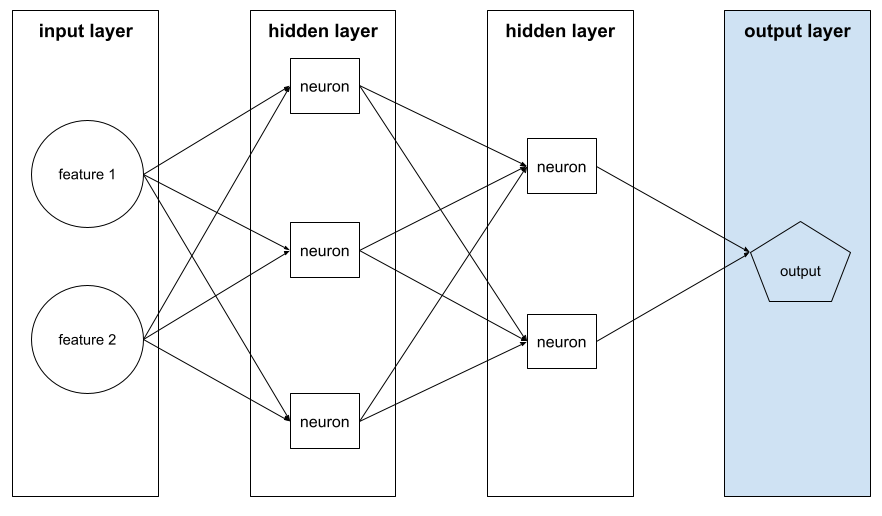
output layer
The "final" layer of a neural network. The output layer contains the prediction.
The following illustration shows a small deep neural network with an input layer, two hidden layers, and an output layer:
переоснащение
Creating a model that matches the training data so closely that the model fails to make correct predictions on new data.
Regularization can reduce overfitting. Training on a large and diverse training set can also reduce overfitting.
П
панды
A column-oriented data analysis API built on top of numpy . Many machine learning frameworks, including TensorFlow, support pandas data structures as inputs. See the pandas documentation for details.
параметр
The weights and biases that a model learns during training . For example, in a linear regression model, the parameters consist of the bias ( b ) and all the weights ( w 1 , w 2 , and so on) in the following formula:
In contrast, hyperparameter are the values that you (or a hyperparameter turning service) supply to the model. For example, learning rate is a hyperparameter.
positive class
The class you are testing for.
For example, the positive class in a cancer model might be "tumor." The positive class in an email classifier might be "spam."
Contrast with negative class .
post-processing
Adjusting the output of a model after the model has been run. Post-processing can be used to enforce fairness constraints without modifying models themselves.
For example, one might apply post-processing to a binary classifier by setting a classification threshold such that equality of opportunity is maintained for some attribute by checking that the true positive rate is the same for all values of that attribute.
прогноз
A model's output. Например:
- The prediction of a binary classification model is either the positive class or the negative class.
- The prediction of a multi-class classification model is one class.
- The prediction of a linear regression model is a number.
proxy labels
Data used to approximate labels not directly available in a dataset.
For example, suppose you must train a model to predict employee stress level. Your dataset contains a lot of predictive features but doesn't contain a label named stress level. Undaunted, you pick "workplace accidents" as a proxy label for stress level. After all, employees under high stress get into more accidents than calm employees. Или они? Maybe workplace accidents actually rise and fall for multiple reasons.
As a second example, suppose you want is it raining? to be a Boolean label for your dataset, but your dataset doesn't contain rain data. If photographs are available, you might establish pictures of people carrying umbrellas as a proxy label for is it raining? Is that a good proxy label? Possibly, but people in some cultures may be more likely to carry umbrellas to protect against sun than the rain.
Proxy labels are often imperfect. When possible, choose actual labels over proxy labels. That said, when an actual label is absent, pick the proxy label very carefully, choosing the least horrible proxy label candidate.
Р
RAG
Abbreviation for retrieval-augmented generation .
оценщик
A human who provides labels for examples . "Annotator" is another name for rater.
Rectified Linear Unit (ReLU)
An activation function with the following behavior:
- If input is negative or zero, then the output is 0.
- If input is positive, then the output is equal to the input.
Например:
- If the input is -3, then the output is 0.
- If the input is +3, then the output is 3.0.
Here is a plot of ReLU:
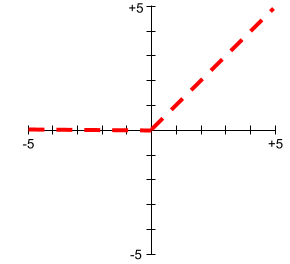
ReLU is a very popular activation function. Despite its simple behavior, ReLU still enables a neural network to learn nonlinear relationships between features and the label .
регрессионная модель
Informally, a model that generates a numerical prediction. (In contrast, a classification model generates a class prediction.) For example, the following are all regression models:
- A model that predicts a certain house's value, such as 423,000 Euros.
- A model that predicts a certain tree's life expectancy, such as 23.2 years.
- A model that predicts the amount of rain that will fall in a certain city over the next six hours, such as 0.18 inches.
Two common types of regression models are:
- Linear regression , which finds the line that best fits label values to features.
- Logistic regression , which generates a probability between 0.0 and 1.0 that a system typically then maps to a class prediction.
Not every model that outputs numerical predictions is a regression model. In some cases, a numeric prediction is really just a classification model that happens to have numeric class names. For example, a model that predicts a numeric postal code is a classification model, not a regression model.
регуляризация
Any mechanism that reduces overfitting . Popular types of regularization include:
- L 1 regularization
- L 2 regularization
- dropout regularization
- early stopping (this is not a formal regularization method, but can effectively limit overfitting)
Regularization can also be defined as the penalty on a model's complexity.
regularization rate
A number that specifies the relative importance of regularization during training. Raising the regularization rate reduces overfitting but may reduce the model's predictive power. Conversely, reducing or omitting the regularization rate increases overfitting.
ReLU
Abbreviation for Rectified Linear Unit .
retrieval-augmented generation (RAG)
A technique for improving the quality of large language model (LLM) output by grounding it with sources of knowledge retrieved after the model was trained. RAG improves the accuracy of LLM responses by providing the trained LLM with access to information retrieved from trusted knowledge bases or documents.
Common motivations to use retrieval-augmented generation include:
- Increasing the factual accuracy of a model's generated responses.
- Giving the model access to knowledge it was not trained on.
- Changing the knowledge that the model uses.
- Enabling the model to cite sources.
For example, suppose that a chemistry app uses the PaLM API to generate summaries related to user queries. When the app's backend receives a query, the backend:
- Searches for ("retrieves") data that's relevant to the user's query.
- Appends ("augments") the relevant chemistry data to the user's query.
- Instructs the LLM to create a summary based on the appended data.
ROC (receiver operating characteristic) Curve
A graph of true positive rate versus false positive rate for different classification thresholds in binary classification.
The shape of an ROC curve suggests a binary classification model's ability to separate positive classes from negative classes. Suppose, for example, that a binary classification model perfectly separates all the negative classes from all the positive classes:
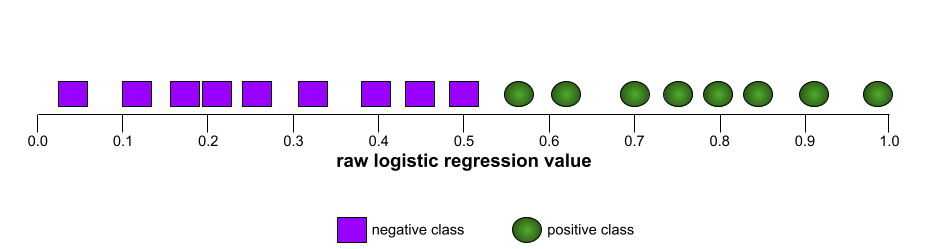
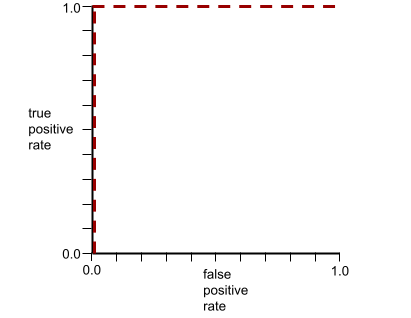
The ROC curve for the preceding model looks as follows:
In contrast, the following illustration graphs the raw logistic regression values for a terrible model that can't separate negative classes from positive classes at all:
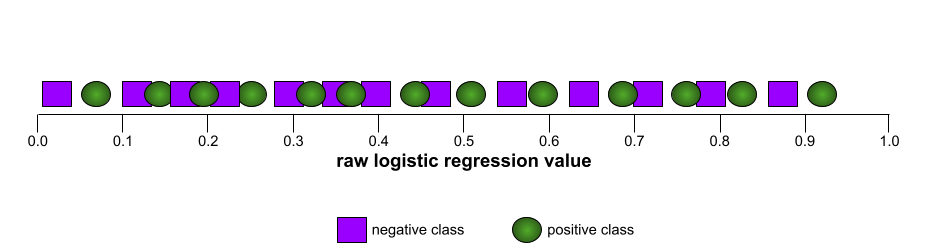
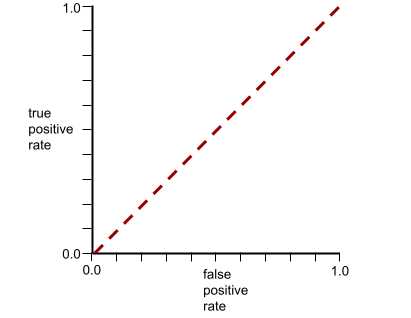
The ROC curve for this model looks as follows:
Meanwhile, back in the real world, most binary classification models separate positive and negative classes to some degree, but usually not perfectly. So, a typical ROC curve falls somewhere between the two extremes:
The point on an ROC curve closest to (0.0,1.0) theoretically identifies the ideal classification threshold. However, several other real-world issues influence the selection of the ideal classification threshold. For example, perhaps false negatives cause far more pain than false positives.
A numerical metric called AUC summarizes the ROC curve into a single floating-point value.
Среднеквадратическая ошибка (RMSE)
The square root of the Mean Squared Error .
С
сигмовидная функция
A mathematical function that "squishes" an input value into a constrained range, typically 0 to 1 or -1 to +1. That is, you can pass any number (two, a million, negative billion, whatever) to a sigmoid and the output will still be in the constrained range. A plot of the sigmoid activation function looks as follows:
The sigmoid function has several uses in machine learning, including:
- Converting the raw output of a logistic regression or multinomial regression model to a probability.
- Acting as an activation function in some neural networks.
softmax
A function that determines probabilities for each possible class in a multi-class classification model . The probabilities add up to exactly 1.0. For example, the following table shows how softmax distributes various probabilities:
| Image is a... | Вероятность |
|---|---|
| собака | .85 |
| кот | .13 |
| лошадь | .02 |
Softmax is also called full softmax .
Contrast with candidate sampling .
sparse feature
A feature whose values are predominately zero or empty. For example, a feature containing a single 1 value and a million 0 values is sparse. In contrast, a dense feature has values that are predominantly not zero or empty.
In machine learning, a surprising number of features are sparse features. Categorical features are usually sparse features. For example, of the 300 possible tree species in a forest, a single example might identify just a maple tree . Or, of the millions of possible videos in a video library, a single example might identify just "Casablanca."
In a model, you typically represent sparse features with one-hot encoding . If the one-hot encoding is big, you might put an embedding layer on top of the one-hot encoding for greater efficiency.
sparse representation
Storing only the position(s) of nonzero elements in a sparse feature.
For example, suppose a categorical feature named species identifies the 36 tree species in a particular forest. Further assume that each example identifies only a single species.
You could use a one-hot vector to represent the tree species in each example. A one-hot vector would contain a single 1 (to represent the particular tree species in that example) and 35 0 s (to represent the 35 tree species not in that example). So, the one-hot representation of maple might look something like the following:

Alternatively, sparse representation would simply identify the position of the particular species. If maple is at position 24, then the sparse representation of maple would simply be:
24
Notice that the sparse representation is much more compact than the one-hot representation.
Click the icon for a slightly more complex example.
Suppose each example in your model must represent the words—but not the order of those words—in an English sentence. English consists of about 170,000 words, so English is a categorical feature with about 170,000 elements. Most English sentences use an extremely tiny fraction of those 170,000 words, so the set of words in a single example is almost certainly going to be sparse data.
Consider the following sentence:
My dog is a great dog
You could use a variant of one-hot vector to represent the words in this sentence. In this variant, multiple cells in the vector can contain a nonzero value. Furthermore, in this variant, a cell can contain an integer other than one. Although the words "my", "is", "a", and "great" appear only once in the sentence, the word "dog" appears twice. Using this variant of one-hot vectors to represent the words in this sentence yields the following 170,000-element vector:

A sparse representation of the same sentence would simply be:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
sparse vector
A vector whose values are mostly zeroes. See also sparse feature and sparsity .
squared loss
Synonym for L 2 loss .
статический
Something done once rather than continuously. The terms static and offline are synonyms. The following are common uses of static and offline in machine learning:
- static model (or offline model ) is a model trained once and then used for a while.
- static training (or offline training ) is the process of training a static model.
- static inference (or offline inference ) is a process in which a model generates a batch of predictions at a time.
Contrast with dynamic .
static inference
Synonym for offline inference .
стационарность
A feature whose values don't change across one or more dimensions, usually time. For example, a feature whose values look about the same in 2021 and 2023 exhibits stationarity.
In the real world, very few features exhibit stationarity. Even features synonymous with stability (like sea level) change over time.
Contrast with nonstationarity .
stochastic gradient descent (SGD)
A gradient descent algorithm in which the batch size is one. In other words, SGD trains on a single example chosen uniformly at random from a training set .
supervised machine learning
Training a model from features and their corresponding labels . Supervised machine learning is analogous to learning a subject by studying a set of questions and their corresponding answers. After mastering the mapping between questions and answers, a student can then provide answers to new (never-before-seen) questions on the same topic.
Compare with unsupervised machine learning .
synthetic feature
A feature not present among the input features, but assembled from one or more of them. Methods for creating synthetic features include the following:
- Bucketing a continuous feature into range bins.
- Creating a feature cross .
- Multiplying (or dividing) one feature value by other feature value(s) or by itself. For example, if
aandbare input features, then the following are examples of synthetic features:- ab
- 2
- Applying a transcendental function to a feature value. For example, if
cis an input feature, then the following are examples of synthetic features:- sin(c)
- ln(c)
Features created by normalizing or scaling alone are not considered synthetic features.
Т
test loss
A metric representing a model's loss against the test set . When building a model , you typically try to minimize test loss. That's because a low test loss is a stronger quality signal than a low training loss or low validation loss .
A large gap between test loss and training loss or validation loss sometimes suggests that you need to increase the regularization rate .
обучение
The process of determining the ideal parameters (weights and biases) comprising a model . During training, a system reads in examples and gradually adjusts parameters. Training uses each example anywhere from a few times to billions of times.
training loss
A metric representing a model's loss during a particular training iteration. For example, suppose the loss function is Mean Squared Error . Perhaps the training loss (the Mean Squared Error) for the 10th iteration is 2.2, and the training loss for the 100th iteration is 1.9.
A loss curve plots training loss versus the number of iterations. A loss curve provides the following hints about training:
- A downward slope implies that the model is improving.
- An upward slope implies that the model is getting worse.
- A flat slope implies that the model has reached convergence .
For example, the following somewhat idealized loss curve shows:
- A steep downward slope during the initial iterations, which implies rapid model improvement.
- A gradually flattening (but still downward) slope until close to the end of training, which implies continued model improvement at a somewhat slower pace then during the initial iterations.
- A flat slope towards the end of training, which suggests convergence.
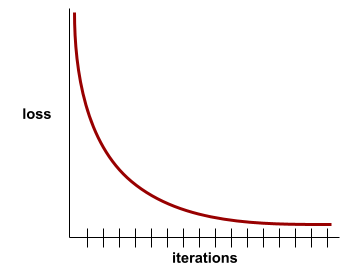
Although training loss is important, see also generalization .
training-serving skew
The difference between a model's performance during training and that same model's performance during serving .
обучающий набор
The subset of the dataset used to train a model .
Traditionally, examples in the dataset are divided into the following three distinct subsets:
- a training set
- a validation set
- a test set
Ideally, each example in the dataset should belong to only one of the preceding subsets. For example, a single example shouldn't belong to both the training set and the validation set.
true negative (TN)
An example in which the model correctly predicts the negative class . For example, the model infers that a particular email message is not spam , and that email message really is not spam .
true positive (TP)
An example in which the model correctly predicts the positive class . For example, the model infers that a particular email message is spam, and that email message really is spam.
true positive rate (TPR)
Synonym for recall . То есть:
True positive rate is the y-axis in an ROC curve .
ты
underfitting
Producing a model with poor predictive ability because the model hasn't fully captured the complexity of the training data. Many problems can cause underfitting, including:
- Training on the wrong set of features .
- Training for too few epochs or at too low a learning rate .
- Training with too high a regularization rate .
- Providing too few hidden layers in a deep neural network.
unlabeled example
An example that contains features but no label . For example, the following table shows three unlabeled examples from a house valuation model, each with three features but no house value:
| Количество спален | Количество ванных комнат | House age |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
In supervised machine learning , models train on labeled examples and make predictions on unlabeled examples .
In semi-supervised and unsupervised learning, unlabeled examples are used during training.
Contrast unlabeled example with labeled example .
unsupervised machine learning
Training a model to find patterns in a dataset, typically an unlabeled dataset.
The most common use of unsupervised machine learning is to cluster data into groups of similar examples. For example, an unsupervised machine learning algorithm can cluster songs based on various properties of the music. The resulting clusters can become an input to other machine learning algorithms (for example, to a music recommendation service). Clustering can help when useful labels are scarce or absent. For example, in domains such as anti-abuse and fraud, clusters can help humans better understand the data.
Contrast with supervised machine learning .
В
проверка
The initial evaluation of a model's quality. Validation checks the quality of a model's predictions against the validation set .
Because the validation set differs from the training set , validation helps guard against overfitting .
You might think of evaluating the model against the validation set as the first round of testing and evaluating the model against the test set as the second round of testing.
validation loss
A metric representing a model's loss on the validation set during a particular iteration of training.
See also generalization curve .
validation set
The subset of the dataset that performs initial evaluation against a trained model . Typically, you evaluate the trained model against the validation set several times before evaluating the model against the test set .
Traditionally, you divide the examples in the dataset into the following three distinct subsets:
- a training set
- a validation set
- a test set
Ideally, each example in the dataset should belong to only one of the preceding subsets. For example, a single example shouldn't belong to both the training set and the validation set.
Вт
масса
A value that a model multiplies by another value. Training is the process of determining a model's ideal weights; inference is the process of using those learned weights to make predictions.
взвешенная сумма
The sum of all the relevant input values multiplied by their corresponding weights. For example, suppose the relevant inputs consist of the following:
| входное значение | input weight |
| 2 | -1,3 |
| -1 | 0,6 |
| 3 | 0,4 |
The weighted sum is therefore:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
A weighted sum is the input argument to an activation function .
З
Z-score normalization
A scaling technique that replaces a raw feature value with a floating-point value representing the number of standard deviations from that feature's mean. For example, consider a feature whose mean is 800 and whose standard deviation is 100. The following table shows how Z-score normalization would map the raw value to its Z-score:
| Raw value | Z-score |
|---|---|
| 800 | 0 |
| 950 | +1,5 |
| 575 | -2,25 |
The machine learning model then trains on the Z-scores for that feature instead of on the raw values.