本頁包含語言評估詞彙表字詞。如要查看所有詞彙字詞 請按這裡。
A
注意力
用於類神經網路的機制 瞭解某個字詞或某部分的重要性壓縮注意力 預測下一個符記/字詞時需要的資訊量。 典型的注意力機制可能包含 加權總和。 每個輸入的 weight 是由 前饋類神經網路
另請參閱「自註意」和 多頭自我注意力,也就是 Transformer 的構成要素。
自動編碼器
學習如何從 。自動編碼器是結合編碼器和 解碼器。自動編碼器必須遵循以下兩個步驟:
- 編碼器會將輸入內容對應至有損或低維度的 (中間) 格式。
- 解碼器會對應以 從較低維度到原始的高階格式 輸入格式
自動編碼器則是由解碼器 透過編碼器轉介格式重新建構原始輸入內容 轉介格式較小 (小於原始格式),則強制使用自動編碼器。 瞭解輸入內容中不可或缺的資訊 與輸入內容完全相同
例如:
- 如果輸入資料是圖形,則非完全副本會是 原始圖形但稍有修改的部分或許是 非完全比對的文案可消除原始圖像或填充雜訊 缺少像素
- 如果輸入資料是文字,自動編碼器會產生新文字 模仿 (但並非完全相同) 的原始文字。
另請參閱變分自動編碼器。
自動迴歸模型
一種模型,可根據模型本身的過去 預測結果例如,自迴歸語言模型 token。 所有 Transformer 為基礎 大型語言模型會自動迴歸。
相反地,GAN 型圖片模型通常不會自動迴歸 因為這類模型產生一張圖像 100 萬步的訓練不過,部分圖像生成模型「會」自動迴歸,原因是 模型就會逐步生成圖像
B
一堆單字
表示詞組或段落中的字詞 無論順序為何例如,字詞袋代表 以下三個詞組必須完全相同:
- 狗跳躍
- 跳狗跳
- 狗在跳躍
每個字詞都會對應到稀疏向量中的索引,其中 在向量中,每個字詞都有一個索引例如: the dogJumps 這個詞組對應至了非 0 的特徵向量 位於三個索引,分別代表 the、dog 和 jumps。非零值可以是下列任一值:
- 1 代表字詞是否存在。
- 一個字詞出現在包包中的次數。例如: 如果該詞組是「暗紅色狗狗 是杯狀毛」,則兩者皆是 「maroon」和「dog」會以 2 表示,其他字詞則以 2 表示 以 1 表示。
- 其他值,例如 代表包包中出現特定字詞的次數
BERT (雙向編碼器) Transformer 的表示法)
文字表示法的模型架構。訓練完成後 BERT 模型可做為大型文字分類或 執行其他機器學習任務
BERT 具備下列特性:
- 採用 Transformer 架構,因此會仰賴 瞭解自註意力。
- 使用轉換器的編碼器部分。編碼器的作用 是要產生良好的文字表示法 就像分類一樣
- 為「雙向性」。
- 用途遮蓋功能: 非監督式訓練。
BERT 的變化版本包括:
,瞭解如何調查及移除這項存取權。請參閱「開放 BERT:Natural Language 最先進的預先訓練」 處理中 ,瞭解 BERT 的總覽
雙向
這個詞彙是用來描述系統評估同時「之前」的文字 然後遵循目標部分的文字。相對地 僅限單向系統 用於評估「前方」文字目標區段的文字。
比方說,假設有遮罩的語言模型 必須判定代表底線的字詞或詞組 下列問題:
你有哪些 _____?
單向語言模型只能根據機率 顯示「What」、「is」和「the」等字詞。相對地 雙向語言模型也能透過「使用」以及「您」, 有助於模型產生更準確的預測結果
雙向語言模型
一種語言模型,可判定 特定符記會引用至指定位置, 上一個和後續文字。
Bigram
其中 N=2 的 N 語法。
BLEU (雙語評估研究)
介於 0.0 到 1.0 (含) 之間的分數,表示翻譯品質 。BLEU 1.0 分表示這是完美的翻譯BLEU 分數為 0.0 分,表示 糟糕的翻譯
C
因果語言模型
單向語言模型的同義詞。
請參閱雙向語言模型以瞭解 對比語言模型的不同方向方法
思維鏈提示
提示工程技術: 大型語言模型 (LLM) 一步一腳印舉例來說,請思考 請特別留意第二句話:
一輛大小從 0 到 60 的車輛會有幾公力 英里數?在答案中顯示所有相關計算。
LLM 可能會回覆:
- 顯示一系列物理公式,將值插入 0、60 和 7 適當的位置。
- 說明為何選擇這些公式,以及各種變數的意義。
思維鏈提示會強制 LLM 執行所有計算 這可能帶來更正確的答案此外,思維鏈 能讓使用者檢查 LLM 的步驟,以判斷 或回答不合理
對話
透過機器學習系統來回對話的內容,通常是 大型語言模型。 先前的即時通訊互動記錄 (您輸入的內容以及大型語言模型的回應方式) 對話後續部分的背景資訊
「聊天機器人」是大型語言模型的應用程式。
探討
hallucination 的同義詞。
說法可能從技術上來說是比幻覺更準確。 然而,幻覺變得很受歡迎。
選區剖析
將句子分割為更小的文法結構 (「組成」)。 機器學習系統的後續部分 自然語言理解模型 比原始語句更容易剖析組成例如: 請考慮以下句子:
我的朋友養育兩隻貓,
組成剖析器可將這個句子分為下列內容: 兩個組成部分:
- 「我的朋友」是一個名詞片語。
- 領養兩隻貓是一種動詞片語。
這些組成項目可以進一步細分為較小的組成部分。 例如:動詞語句
領養兩隻貓
可進一步細分為
- adopted 為動詞。
- 「兩隻貓」是另一個名詞片語。
情境化語言嵌入
接近「理解」的嵌入字詞 做出貢獻情境語言 嵌入能理解複雜的語法、語意和背景資訊。
舉例來說,請考慮使用英文「cow」的嵌入項目。較舊的嵌入 例如 word2vec 可以表示英文 例如加入嵌入空間的距離 從牛到公牛,與女性 (女性綿羊) 的距離相近 ram (男性羊) 或從女性改為男性。情境語言 並能辨識英文使用者有時會 隨意使用「cow」這個字詞來表示牛或公牛。
上下文窗口
模型可在指定時間內處理的符記數量 提示。背景區間越大,更多資訊 模型能用來提供連貫且一致的回應 都沒有問題
衝刺風潮
意思不清楚的句子或詞組。 爆裂物的「自然」問題 語言理解程度。 舉例來說,紅色 Tape 保持摩天大樓這個標題是 NLU 模型能直接解讀標題文字 跳脫現實的框架
D
解碼器
一般來說,任何機器學習系統 透過經過處理、稠密或稠密的方式 產生更原始、稀疏或外部表示法的內部表示法。
解碼器通常是較大型模型的元件 與編碼器配對。
在「序列至序列工作」中,解碼器 開頭是編碼器產生的內部狀態 序列
如要瞭解在Transformer Transformer 架構
雜訊
自監督學習的常見做法 出現以下情況:
- 您會在資料集中手動新增雜訊。
- 「模型」會嘗試移除雜訊。
去除雜訊有助於從未加上標籤的範例中學習。 原始的資料集會做為目標 label 和 做為輸入內容
某些遮蓋的語言模型會採用去除雜訊功能 如下所示:
- 為無標籤的句子加上雜訊, 符記
- 模型會嘗試預測原始符記。
直接提示
零樣本提示的同義詞。
E
編輯距離
測量兩個文字字串彼此相似程度的測量結果。 在機器學習中,編輯距離是很實用的做法 ,並有效比較兩個已知且 或找出與指定字串類似的字串
編輯距離有幾種定義,每個欄位分別使用不同的字串 作業。舉例來說, Levenshtein 距離 會考量最少的刪除、插入和替代作業
例如「Heart」字詞之間的 Levenshtein 距離和「飛鏢」 是 3,因為後續 3 次修改是轉化成一個字的最少 複製到另一個:
- Heart → deart (以「d」取代「h」)
- deart → dart (刪除「e」)
- 飛鏢 → 飛鏢 (輸入「s」)
嵌入層
特殊隱藏層,可在 高維度類別特徵 會逐漸學習較低維度的嵌入向量一個 嵌入層可讓類神經網路 比單純訓練高維度類別特徵來得有效率
舉例來說,Google 地球目前大約支援 73,000 種樹木。假設
樹種是模型中的特徵,
輸入層包括一個 one-hot 向量 73,000
個元素。
例如,也許 baobab 應表示如下:

73,000 元素的陣列太長。如未新增嵌入層 因此訓練非常耗時 乘以 72,999 個零您可以選擇要納入的嵌入層 12 個維度因此嵌入層會逐漸學習 為各個樹種建立全新的嵌入向量
在某些情況下,雜湊處理是合理的替代方案 加入嵌入層
嵌入空間
來自較高維度的 DD 向量空間 對應至向量空間在理想情況下,嵌入空間會包含 產生有意義的數學結果例如 在理想的嵌入空間中,加上加減法 就能完成文字類比任務
內積產品 是兩個嵌入的相似度。
嵌入向量
大致上來說,這是從任何值中擷取的浮點數陣列 隱藏層,用於描述該隱藏層的輸入內容。 通常,嵌入向量是由 包括嵌入層舉例來說,假設嵌入層必須學習 為地球上 73,000 棵樹種 1 個嵌入向量。或許是 下列陣列是麵包樹的嵌入向量:

嵌入向量並非隨機數字。嵌入層 透過訓練決定這些值 類神經網路會在訓練過程中學習其他權重該元件的每個元素 是樹木物種特定特性的評分模型哪一個? 元素代表特性?這太難了 以便人類判斷
以數學向量來說 項目的浮點數集合相近。例如 樹類物種的浮點數會比 不同的樹種紅木和紅杉是相關的樹種 因此會擁有一組比浮點數更相似的浮點數 紅木和椰子棕櫚樹嵌入向量的數字 每次重新訓練模型時都要變更 輸出的內容
編碼器
一般而言,任何機器學習系統 可從原始、稀疏或外部 會以較經過處理、較密集或較內部的方式呈現。
編碼器通常是較大型模型的元件,且常用於 與解碼器配對。部分轉換器 將編碼器與解碼器配對,但其他 Transformer 只會使用編碼器 或只用解碼器
部分系統會使用編碼器的輸出內容做為分類或分類的輸入內容 迴歸網路
在「序列至序列工作」中,編碼器 會接收輸入序列,並傳回內部狀態 (向量)。接著, 解碼器會使用內部狀態預測下一個序列。
請參閱Transformer,瞭解 Transformer 架構
F
少量樣本提示
包含多個提示 (「少數」) 的範例 示範大型語言模型 回應。舉例來說, 顯示大型語言模型如何回答查詢的範例。
| 單一提示的組成部分 | 附註 |
|---|---|
| 指定國家/地區的官方貨幣為何? | 您希望 LLM 回答的問題。 |
| 法國:EUR | 我們來看個個例子 |
| 英國:GBP | 另一個例子 |
| 印度: | 實際查詢。 |
少量樣本提示產生的結果通常比 零樣本提示和 單樣本提示。不過,少量樣本提示 就需要較長的提示
小提琴
以 Python 優先的設定程式庫,目的是設定 完全不需要侵入式程式碼或基礎架構。 以 Pax 和其他機器學習程式碼集來說,這類函式和 類別代表模型和訓練 「超參數」。
小提琴 假設機器學習程式碼集通常分為:
- 程式庫程式碼,可定義圖層和最佳化器。
- 資料集「glue」程式碼,用於呼叫程式庫並將所有內容連接在一起。
Fiddle 會在未評估的 可變動的形式
微調
並在 預先訓練模型來修正參數 特定用途舉例來說 大型語言模型的運作方式如下:
- 預先訓練:使用龐大的「一般」資料集訓練大型語言模型。 例如所有英文的 Wikipedia 網頁
- 微調:訓練預先訓練模型來執行「特定」工作。 例如回應醫療查詢微調通常包括 或成千上萬個以特定工作為主的範例。
再舉一個例子,大型圖片模型的完整訓練序列是 如下:
- 預先訓練:使用龐大一般圖片訓練大型圖片模型 例如 Wikimedia Commons 的所有圖片
- 微調:訓練預先訓練模型來執行「特定」工作。 例如產生虎鯨的圖片
微調功能可以將下列策略組合搭配運用:
- 修改「所有」預先訓練模型的現有模型 參數。這有時也稱為「完整微調」。
- 只修改部分預先訓練模型的現有參數 (通常是最接近輸出層的層)。 同時保留其他現有參數 (通常為 最接近輸入層)。詳情請見 具參數運用效率的調整作業。
- 新增更多圖層,通常是在最靠近 輸出層
微調是遷移學習的一種方式, 因此,微調可能會使用不同的損失函式或不同的模型 而不是用於訓練預先訓練模型的類型例如,您可以 微調預先訓練的大型圖片模型,產生迴歸模型 會傳回輸入圖片中的鳥類數量。
下列詞彙的比較及對比:
亞麻色
高效能的開放原始碼 程式庫 以 JAX 為基礎建構的深度學習技術。Flax 提供函式 適用於訓練 類神經網路 評估廣告成效
Flaxformer
開放原始碼 Transformer library 建構於 Flax,主要用於自然語言處理 以及多模態研究
G
生成式 AI
沒有正式定義的新興轉換欄位。 不過,多數專家都認同生成式 AI 模型可以 建立 (「產生」) 符合下列所有條件的內容:
- 複雜
- 連貫性
- 原始圖片
例如生成式 AI 模型 文章或圖片
某些早期技術,包括 LSTMs 和 RNN 也能產生 連貫的內容部分專家認為這些早期技術是 有些人則認為,真正的生成式 AI 需要更複雜 這些模型產生的輸出內容會比早期技術
與預測式機器學習相反。
GPT (生成式預先訓練 Transformer)
以 Transformer 為基礎 由 Google 開發的大型語言模型 OpenAI。
GPT 變化版本可適用於多種模式,包括:
- 圖像生成 (例如 ImageGPT)
- 生成文字轉圖片 (例如 DALL-E)。
H
幻覺
產生的看似合理,但輸出內容與事實不符 生成式 AI 模型 對現實世界的聲明 舉例來說,生成式 AI 模型宣稱歐巴馬在 1865 年過世 減碳。
I
情境學習
少量樣本提示的同義詞。
L
LaMDA (對話應用程式的語言模型)
以 Transformer 為基礎的 由 Google 開發的大型語言模型 能生成真實對話回應的大型對話資料集。
語言模型
大型語言模型
沒有嚴格定義的非正式字詞,通常表示 各種版本的語言模型 參數。 某些大型語言模型包含超過 1,000 億個參數。
潛在空間
嵌入空間的同義詞。
LLM
大型語言模型的縮寫。
LoRA
低階適應性的縮寫。
低階適應性 (LoRA)
用於執行相關作業的演算法 「有效調整參數」, 只有一小部分的媒體內容 大型語言模型的參數。 LoRA 優點如下:
- 相較於需要微調模型「所有」的技術,加速微調作業速度 參數。
- 降低推論的計算成本 經過微調的模型
透過 LoRA 調整的模型會維持或提升預測品質。
LoRA 支援單一模型的多個專屬版本。
M
遮蓋的語言模型
一種語言模型,能預測 序列中要填入的候選符記。舉例來說, 遮蓋的語言模型可以計算候選字詞的機率 取代下一句的底線:
帽子的 ____ 回來了。
文獻使用字串「MASK」而不是底線 例如:
《MASK》帽子又回來了
大多數新型遮蓋的語言模型都是雙向遮蓋語言。
中繼學習
是機器學習技術的分支,可探索或改進機器學習演算法。 元學習系統也可以用來訓練模型,快速學習新的 少量資料或先前工作所獲得的經驗 中繼學習演算法通常會嘗試達到以下目標:
- 改善或學習手動工程的功能 (例如初始化或 最佳化器)。
- 提高資料效率和運算效率。
- 提升一般化。
中繼學習與少量樣本學習有關。
形態
概略資料類別。例如數字、文字、圖片、影片 音訊有兩種形式
模型平行處理
一種是調度訓練或推論資源,將不同部分 型號。模型平行處理 就能讓太大的模型無法支援單一裝置。
如要實作模型平行處理,系統通常會執行以下操作:
- 將模型分割為更小的部分。
- 將這些較小部分的訓練分散於多個處理器上。 每個處理器都會訓練自己的模型部分。
- 合併結果以建立單一模型。
模型平行處理會降低訓練速度。
另請參閱資料平行處理。
多頭自我注意力
自註意力的延伸,會套用 自我注意力機制會多次影響輸入序列中的每個位置。
Transformer 導入多頭自我注意力機制。
多模態模型
輸入和/或輸出內容包含多個項目的模型 modality:舉例來說,假設模型可同時接收 圖片和文字說明文字 (兩種形式) 為「功能」,以及 會輸出一個分數,指出文字說明文字是否適合該圖片。 因此,這個模型的輸入內容屬於多模態,且輸出內容為單模。
否
自然語言理解
根據使用者輸入或說話的內容判斷使用者的意圖。 舉例來說,搜尋引擎會利用自然語言理解技術 根據使用者輸入或說話的內容,判斷要搜尋什麼內容。
N 克
N 個字詞的排序序列。例如,「truly madly」是 2 公克由於 順序相關,但「必須真正」與「完全瘋狂」不同的 2 公克圖像。
| 否 | 這類 N 元語法的名稱 | 範例 |
|---|---|---|
| 2 | Biram 或 2 公克 | 去、吃午餐、吃晚餐 |
| 3 | 三角形或 3 公克 | 丟了太多葉子、三個盲滑鼠、鈴鐺 |
| 4 | 4 公克 | 公園裡的步道、風吹灰塵、男孩放著扁豆 |
多重自然語言理解 模型會根據 N 元語法預測使用者接下來要輸入的 或說出來例如,假設使用者輸入「three blind」。 以三角為基礎的 NLU 模型 下一個使用者輸入 mice。
比較 N 克和詞袋的對比度,
自然語言理解
O
單樣本提示
提示,內含一個範例,以便示範 大型語言模型應該會有所回應。例如: 在以下提示中,有一個範例顯示了大型語言模型 應能回答查詢
| 單一提示的組成部分 | 附註 |
|---|---|
| 指定國家/地區的官方貨幣為何? | 您希望 LLM 回答的問題。 |
| 法國:EUR | 我們來看個個例子 |
| 印度: | 實際查詢。 |
比較並對照下列字詞:單樣本提示:
P
高效參數調整
大規模微調 預先訓練的語言模型 (PLM) 比完整微調更有效率。具參數運用效率 調整作業的參數通常比完整參數少 一般而言 能執行工作負載的大型語言模型 以及幾乎也能採用 微調的部分
比較具參數運用效率的調整方法:
具參數運用效率的調整方法,也稱為「具參數運用效率的微調」。
管道
一種模型平行處理形式, 會分為多個連續階段 在其他裝置上階段會處理一個批次 處理下一個批次工作
另請參閱階段訓練。
PLM
預先訓練的語言模型的縮寫。
位置編碼
一種用於新增序列符記「位置」相關資訊的技巧, 符記嵌入Transformer 模型使用位置 編碼,深入瞭解不同部分 序列
位置編碼的常見實作使用 Sinusoidal 函式。 (具體來說,正弦函數的頻率和振幅為 而取決於序列中符記的位置)。這項技巧 Transformer 模型能學習訓練 根據其位置排列
預先訓練模型
模型或模型元件 (例如 嵌入向量)。 有時候,您會將預先訓練的嵌入向量提供給 「類神經網路」其他時候,模型就會訓練 嵌入向量,而非依賴預先訓練的嵌入。
「預先訓練模型」一詞是指 目前已經歷的大型語言模型 預先訓練。
預先訓練
以大型資料集訓練模型的初始訓練。某些預先訓練模型 通常都是笨蛋,必須通過額外訓練才能加以修正 舉例來說,機器學習專家可能會預先訓練 大型文字資料集的大型語言模型 例如維基百科中的所有英文網頁預先訓練後 而產生的模型可能會透過下列任一指令進一步修正 技巧:
提示
在大型語言模型中輸入的任何文字 條件,讓模型以特定方式運作。提示可以很簡短 詞組或任意長度 (例如小說中的完整文字)。提示 可歸入多個類別,如下表所示:
| 提示類別 | 範例 | 附註 |
|---|---|---|
| 問題 | 鴿子可以飛多快? | |
| 操作說明 | 撰寫有關套利的有趣詩詞。 | 提示,要求大型語言模型「執行」特定操作。 |
| 範例 | 將 Markdown 程式碼翻譯成 HTML。例如:
Markdown:* 清單項目 HTML:<ul><li>清單項目</li></ul> |
這個範例提示的第一句是指令, 提示的其餘部分就是範例。 |
| 角色 | 說明為何在機器學習訓練中使用梯度下降法 以及物理學博士 | 句子的第一部分是指令;詞組 「到物理博士」則是職務的部分 |
| 待模型完成的部分輸入內容 | 英國總理 | 部分輸入提示有可能突然結束 (如本範例所示) 或是以底線結尾。 |
生成式 AI 模型能以文字、提示、 程式碼、圖像、嵌入影片等,幾乎什麼都一樣。
提示式學習
特定模型的功能,可自行調整模型 回應任意文字輸入內容而的行為 (提示)。 在典型的提示式學習範例中 大型語言模型會藉由回應 生成文字舉例來說,假設使用者輸入下列提示:
總結牛頓第三運動定律
未特別訓練 先前的提示而是模型「知識」許多物理知識 以及一般語言規則,以及整體語言規範的許多內容 實用解答這樣的知識足以提供 (非常有幫助) 回答的問題其他人類回饋 (「答案太複雜」或 「什麼是反應?」)可讓部分提示型學習系統逐漸 提供更實用的答案
提示設計
提示工程的同義詞。
提示工程
建立可產生所需回應的提示的技巧 從大型語言模型建立起人類執行提示 在這階段,您必須先上傳並備妥資料 透過特徵工程將資料用於模型訓練撰寫條理分明的提示是確保使用者 以大型語言模型產生實用回應提示工程取決於 許多因素,包括:
- 用來預先訓練,或 精密的大型語言模型。
- temperature 以及 能生成回覆
詳情請見 提示設計簡介 進一步瞭解如何撰寫實用提示。
提示設計是提示工程的同義詞,
提示調整
有效調整參數機制 也就是下一個字詞的開頭會加上 實際的提示。
提示調整的其中一種變化版本 (有時稱為「前置字串調整」) 請在「每個資料層」前方加上前置字元相反地,大部分提示調整作業 將前置字串加入輸入層
R
角色提示
這是提示的選用部分,可用來識別目標對象 讓生成式 AI 模型的回應不具備角色 則大型語言模型提供的答案不一定實用 提問者可以輕鬆獲得解答以角色提示來說 模型該如何回答 目標對象例如,下列所述的角色提示部分 會以粗體顯示提示:
- 請總結這篇文章,瞭解經濟學博士。
- 說明 10 歲的眉毛如何。
- 說明 2008 年金融危機。就像跟年幼的孩子一樣 或黃金擷取器
S
自我注意力層 (也稱為自註意力層)
一種可以轉換序列的類神經網路層 嵌入 (例如 token 嵌入) 轉換成另一個嵌入序列輸出序列中的每個嵌入項目 整合來自輸入序列元素的資訊 注意力機制來保護使用者隱私。
自註意的「自己」部分是指 而非其他情境資訊自我注意力是 轉換工具的構成元素,並使用字典查詢功能 術語,例如「query」、「鍵」和「value」。
自我注意力層從一系列輸入表示法開始 。字詞的輸入表示法 和嵌入的內容對於輸入序列中的每個字詞,網路 計算字詞與序列中每個元素的關聯性 還能分析語法及擷取語言資訊 例如字詞之間的關係關聯性分數會決定字詞最終呈現的程度 融合其他字詞的表示法。
以下列句子為例:
動物太累,所以沒有跨越街道。
下圖 (根據 Transformer:新型類神經網路架構 瞭解) 能顯示人稱代詞的自註意層的注意力模式, 每一行的暗度,代表每個字詞對 表示法:
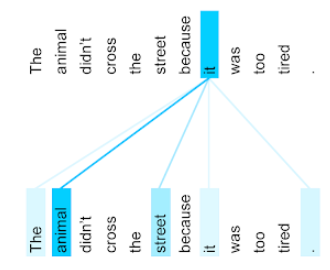
自我注意力層會突顯與「它」相關的字詞。在本 注意力層已經學會如何突顯「它」可能 ,將最高權重指派給「animal」。
對於一串 n 符記,自我注意力會轉換序列 嵌入 n 次,依序列中的每個位置分別輸入一次。
情緒分析
使用統計或機器學習演算法決定群組的 對服務、產品、服務或產品的整體態度 機構或主題舉例來說,使用 自然語言理解、 演算法可以根據文字回饋執行情緒分析 評估學生的學習程度 通常喜歡或不喜歡本課程。
序列對序列工作
此工作可將 tokens 的輸入序列轉換為輸出。 符記序列以這兩種常見的序列至序列為例 工作為:
- 譯者:
- 輸入序列範例:「我愛你」。
- 輸出序列範例:「Je t'aime」。
- 回答問題:
- 輸入序列範例:「我需要在紐約市準備我的車輛嗎?」
- 輸出序列範例:「No.請留在家中。」
skip-gram
可省略 (或「略過」) 原文字詞的 n-gram 換句話說,N 字的意思不一定是相鄰的字詞。更多內容 準確來說就是「k-skip-n-gram」是 n 元語法,最多 k 字 略過。
例如:「快速棕色狐狸」下列可能的 2 公克如下:
- 「快速」
- 「快速棕色」
- 「棕色狐狸」
「1-skip-2 公克」是指兩個字詞中間最多 1 個字詞。 所以,我們要說的是「快速棕色狐狸」下列 1 - 略過 2 公克:
- 「棕色」
- "快速狐狸"
此外,所有 2 公克也是 1-skip-2-grams,因為減少 就會略過
跳轉文字有助於進一步瞭解字詞的前後脈絡。 在這個範例中,「fox」與「快速」直接相關參數集 1-skip-2-grams,但 2 公克集合則否。
跳克數說明訓練 字詞嵌入模型。
軟提示調整
調整大型語言模型的技巧 以執行特定工作 微調。與其重新訓練所有 模型的權重、軟提示調整作業 自動調整提示以達成相同的目標。
收到文字提示時,請微調提示 通常會將額外的權杖嵌入附加至提示,並使用 反向傳播以最佳化輸入
一個「困難」提示含有實際符記,而非符記嵌入。
稀疏特徵
特徵的值主要為零或空白。 舉例來說,包含 1 個值和 100 萬個值的特徵是 稀疏。相反地,稠密特徵的值 通常不是零或空白
在機器學習領域,有許多令人驚訝的特徵是稀疏特徵。 類別特徵通常是稀疏的特徵。 舉例來說,以森林中有 300 種可能的樹種為例, 可能只會辨識楓樹。或是數百萬 一個範例可能會找出 就只要「Casablanca」即可。
在模型中,您通常會使用 one-hot 編碼。如果 one-hot 編碼太大 可以將嵌入層放在 one-hot 編碼來提高效率。
稀疏表示法
在稀疏特徵中僅儲存非零元素的 position(s)。
舉例來說,假設名為 species 的類別特徵識別為 36
可以瞭解特定森林中的大樹種進一步假設
example 只能識別單一物種。
您可以使用 one-hot 向量來表示每個範例中的樹木種類。
單樣本向量會包含單一 1 (代表
在此範例中的特定樹種) 和 35 個 0 (代表
這個例子中「沒有」35 種樹種)。one-hot 表示法
的 maple 可能如下所示:

或者,稀疏表示法只會找出
特定物種如果 maple 位於 24 的位置,則為稀疏表示法
maple 就是:
24
請注意,稀疏表示法比單一樣本更為精簡 這種表示法
按一下圖示即可查看較複雜的範例。
假設模型中的每個範例都必須代表字詞,但不得 字詞的順序 (以英文句子表示)。 英文約為 170,000 字,因此英文是類別型 內含約 170,000 個元素大部分的英文句子都會使用 這 170,000 個字中只有極小一部分,因此稱為 一個例子幾乎肯定都是稀疏資料
請見以下句子:
My dog is a great dog
您可以使用 one-hot 向量的變體來表示 語句在這個變化版本中,向量中的多個儲存格可包含 非零的值此外,在這個變化版本中,儲存格可以包含整數 而非單一雖然「my」、「is」、「a」和「great」等字詞僅顯示 你會在句子中同時加入「狗」這個字詞出現兩次使用這個 API 的變化版本 代表此句子中字詞的 one-hot 向量,會產生下列結果 170,000 個元素的向量:

相同語句的稀疏表示法如下:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
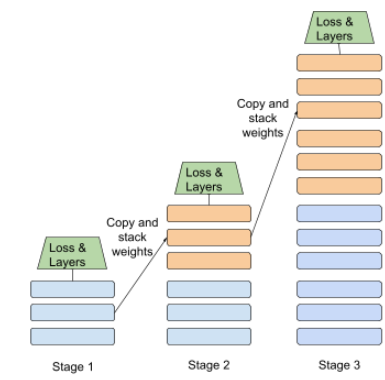
階段訓練
以連續階段訓練模型的方法。目標可以是 加快訓練程序,或提升模型品質
漸進式堆疊方法的插圖如下:
- 第 1 階段包含 3 個隱藏層,第 2 階段含有 6 個隱藏層, 階段 3 含有 12 個隱藏圖層。
- 第二階段從 3 個隱藏層中學到的權重開始訓練 第三階段一開始是利用 隱藏層的隱藏層
另請參閱直線符號。
子字詞符記
例如「itemize」這個字詞可細分為「item」項目 (根字詞) 和「ize」(後置字元),每個結尾都會 產生下一個符記將不常見的字詞拆成「子字詞」 針對更常見的組成部分運作語言模型 例如前置字串和後置字串
相反地,「往來」這類常用的字詞可能並未中斷 代表單一符記
T
T5
文字轉文字遷移學習 模型 推出者: 2020 年 Google AI。 T5 是編碼器-解碼器模型,根據 以極大規模訓練而成的 Transformer 架構 這個模型能有效處理各種自然語言處理工作 例如生成文字、翻譯語言 以對話方式解讀對方
T5 會從「Text-to-Text Transfer Transformer」(文字轉文字轉換轉換) 中的五個 T 取得名稱。
T5X
經過設計的開放原始碼機器學習架構 建構及訓練大規模的自然語言處理作業 (NLP) 模型T5 則是在 T5X 程式碼集上實作 (也就是 以 JAX 和 Flax 為基礎而建構。
溫度
控制隨機程度的超參數 輸出內容隨機性參數越高,輸出量就會越多 降低隨機性參數則能產生較不隨機的輸出內容
最佳溫度的選擇取決於特定的應用和 模型輸出內容的偏好屬性。舉例來說 因此應該在建立應用程式時,調高溫度 產生廣告素材輸出內容反之,最好在 建構模型來分類圖像或文字 準確率與一致性
溫度通常會搭配 softmax 使用。
文字 Span
與文字字串中特定子區段相關聯的陣列索引時距。
例如,Python 字串 s="Be good now" 中的 good 這個字詞會有人使用。
文字範圍從 3 到 6
token
在語言模型中,模型所屬的不可分割單位 來執行預測訓練權杖通常是 包括:
- 例如「狗等貓」詞組由三個字組成 符記:「dogs」、「like」和「cats」。
- 字元,例如「自行車魚」含有九個 字元符記(請注意,空格字元算是其中一個符記)。
- 子字詞,單一字詞可以是單一符記或多個符記。 子字詞是由根字詞、前置字元或後置字元組成。例如: 使用子字詞做為符記的語言模型可能會瀏覽「dogs」一詞 視為兩個符記 (也就是根字詞「dog」和複數字尾「s」)。同理 語言模型可能會檢視「taller」這個單一字詞兩個子字詞 (即 根字詞「tall」加上「er」字尾
在語言模型以外的網域中,符記可以代表 不可分割的單位舉例來說,在電腦視覺中,符記可能是子集 圖片中的文字
Transformer
由 Google 開發的類神經網路架構, 仰賴自註意力機制來轉換 輸入嵌入序列 不必依靠卷積或 循環類神經網路。Transformer 可能是 形成一個自註意力層
轉換器可包含下列項目:
編碼器能將嵌入序列轉換成新的 則不必輸入長度相同的值編碼器包含 N 個相同層,每個層都包含兩個 子層這兩個子圖層會套用至輸入內容的每個位置 也就是將序列中每個元素轉換為新的 和嵌入的內容第一個編碼器子層會匯總 輸入序列第二個編碼器子層 輸出資訊至輸出嵌入
解碼器會將輸入嵌入序列轉換為 可能會擁有不同的長度解碼器也包含 包含三個子圖層的 N 個相同圖層,兩個子層相似 編碼器子層第三個解碼器子層會 並套用自註意力機制, 收集資料
網誌文章「Transformer:語言的新類類神經網路架構 瞭解 也提供 Transformer 的簡介
三角形
包含 N=3 的 N 語法。
U
單向
這個系統只會評估文字「落在」目標區段之前的文字。 相較之下,雙向系統則會評估 前方和後續文字的目標部分。 詳情請參閱雙向模式。
單向語言模型
這種語言模型僅會以 符記會顯示在目標符記「之前」,而非「之後」。 與雙向語言模型的對比。
V
變分自動編碼器 (VAE)
運用差異的自動編碼器 產生修改後的輸入值版本。 變分自動編碼器適合用於生成式 AI。
VAE 是以變化版本推論為基礎,也就是 機率模型的參數
三
字詞嵌入
表示字詞集內字詞集內的每個字詞。 「嵌入向量」;也就是代表每個單字 介於 0.0 和 1.0 之間的浮點值向量相似的字詞 意義的表示法比含不同含意的字詞更多。 舉例來說,「胡蘿蔔」、「塞車」和「小黃瓜」都會是相對的 這兩者之間會非常不同 飛機、太陽眼鏡和牙膏。
Z
零樣本提示
未提供範例的提示,並未提供實際範例 大型語言模型加以回應。例如:
| 單一提示的組成部分 | 附註 |
|---|---|
| 指定國家/地區的官方貨幣為何? | 您希望 LLM 回答的問題。 |
| 印度: | 實際查詢。 |
大型語言模型可能會提供下列其中一項回應:
- 盧比符號
- INR
- ₹
- 印度盧比
- 盧比
- 印度盧比
以上皆是,不過您可能想使用特定格式。
比較零樣本提示與下列字詞: